Reverse Engineering with a Local LLM: Disassembly, Triage, and Frida Hooks
Introduction
Reverse engineering is slow, patient work: you stare at disassembly, build a mental model of what a function does, rename variables, and slowly recover intent from a wall of ldr/str/cbz. A lot of that work is pattern recognition and summarisation — and that is squarely in the wheelhouse of a language model. Over the last two years, AI assistants have quietly become one of the most useful additions to an RE workflow (see the popular Ghidra and IDA plugins that pipe decompiler output to an LLM for renaming and explanation).
In this post we do it with a local, open-source model running offline via Ollama — which matters for RE, because the binaries you analyse are often confidential, malicious, or under NDA, and you do not want to upload them to a third-party API. We take a small ARM64 Mach-O binary, disassemble a license check, ask a local qwen3.6:35b-a3b model to explain it, verify its analysis by forging a valid key, and finally have the model write a working Frida hook to bypass the check. Everything is reproducible on your own machine. This is a taste of the AI-for-mobile-security-testing and AI-for-vulnerability-research modules in Advanced AI Security.
The post is written so a beginner can follow the RE, while staying technical enough to be useful to working researchers. If you already read ARM64 fluently, skim the primer.
📦 Download the lab:
re-local-llm-lab.zip— the target source, the prompts, the LLM’s analysis, and the generated Frida hook. Needs clang + objdump/radare2; Ollama and Frida optional. Analyse only binaries you own or are authorized to test.
Primer: how reverse engineers read a binary (for beginners)
If disassembly looks like noise to you, here is the minimum to follow along.
- Compilation is lossy. Source code (
check_license(...)) becomes machine code. The compiler throws away variable names, comments, and types; what survives is instructions and offsets. RE is the craft of reconstructing intent from what survived. - A disassembler (objdump, radare2, IDA, Ghidra, Binary Ninja) turns raw bytes back into human-readable assembly instructions. A decompiler goes further and produces approximate C. We use
objdumpandradare2here. - ARM64 basics: modern iPhones and Apple Silicon Macs run ARM64. Registers are
x0–x30(64-bit) /w0–w30(32-bit). Function arguments arrive inx0,x1, …; the return value goes back inx0/w0.ldrloads from memory,strstores,add/subsdo arithmetic,cbzbranches if a register is zero,retreturns. - Dynamic instrumentation with Frida lets you attach to a running process and rewrite its behaviour on the fly — intercept a function, read or change its arguments, or force its return value — without patching the binary on disk. It is the workhorse of mobile security testing.
The task in this lab — recovering a license-check algorithm and bypassing it — is a microcosm of real app assessment: understand a security-relevant function, then defeat it.
The target: a license check
The lab compiles this to a Mach-O binary. In a real assessment you would not have the source — you would recover all of this from the disassembly, which is exactly what we ask the model to help with.
int check_license(const char *key) {
int sum = 0;
for (int i = 0; key[i]; i++) sum += key[i];
return sum == 0x539; /* "valid" if the ASCII sum equals 1337 */
}Step 1: disassemble the function
We pull the function’s instructions with objdump (radare2’s pdf @ sym._check_license gives a richer, annotated view — the lab shows both):
clang -g -O0 licensed.c -o licensed
objdump -d licensed | sed -n '/_check_license/,/ret/p'The core of the output is a loop that walks the string and a final comparison:
100000480: ldrb w8, [x8] ; load a byte of the key
100000484: cbz w8, 0x1000004b8 ; if byte == 0 (NUL terminator), exit loop
...
1000004a0: str w8, [sp, #0x4] ; accumulate the running sum
...
1000004bc: subs w8, w8, #0x539 ; compare the sum against 0x539 (1337)
1000004c0: cset w0, eq ; return 1 if equal, else 0To a trained eye the subs w8, w8, #0x539 followed by cset w0, eq is the whole secret: the function returns true when some accumulated value equals 0x539. But recovering “the accumulated value is the byte-sum of the key” from the loop takes a few minutes of careful reading. That summarisation is what we hand to the model.
How you frame the disassembly matters more than the model. The single biggest lever on output quality is what you paste in. Three rules keep the model grounded and cut hallucination:
- Feed one whole function, with addresses and the disassembler’s annotations intact. radare2’s
pdf(shown below) already labels args (arg int64_t arg1 @ x0), stack variables (var_4h @ sp+0x4), and branch targets. Those anchors give the model something concrete to reason about; a headerless, address-stripped blob invites it to invent structure. Keep the function whole so it can see the loop back-edge and the final comparison in one context. - Ask for structured output and low temperature. Request JSON (
{"summary": ..., "renames": {...}}) and settemperaturelow (0.1). You want a literal reading of the bytes in front of it, not fluent prose that drifts. Structured output also makes the answer machine-checkable and easy to write back into the project. - Tell it not to guess. A one-line instruction — “if a value’s origin is unclear, say so rather than inventing one” — measurably reduces confident-but-wrong claims from small local models. The goal is a hypothesis you can verify (Step 3), not an authoritative-sounding conclusion.
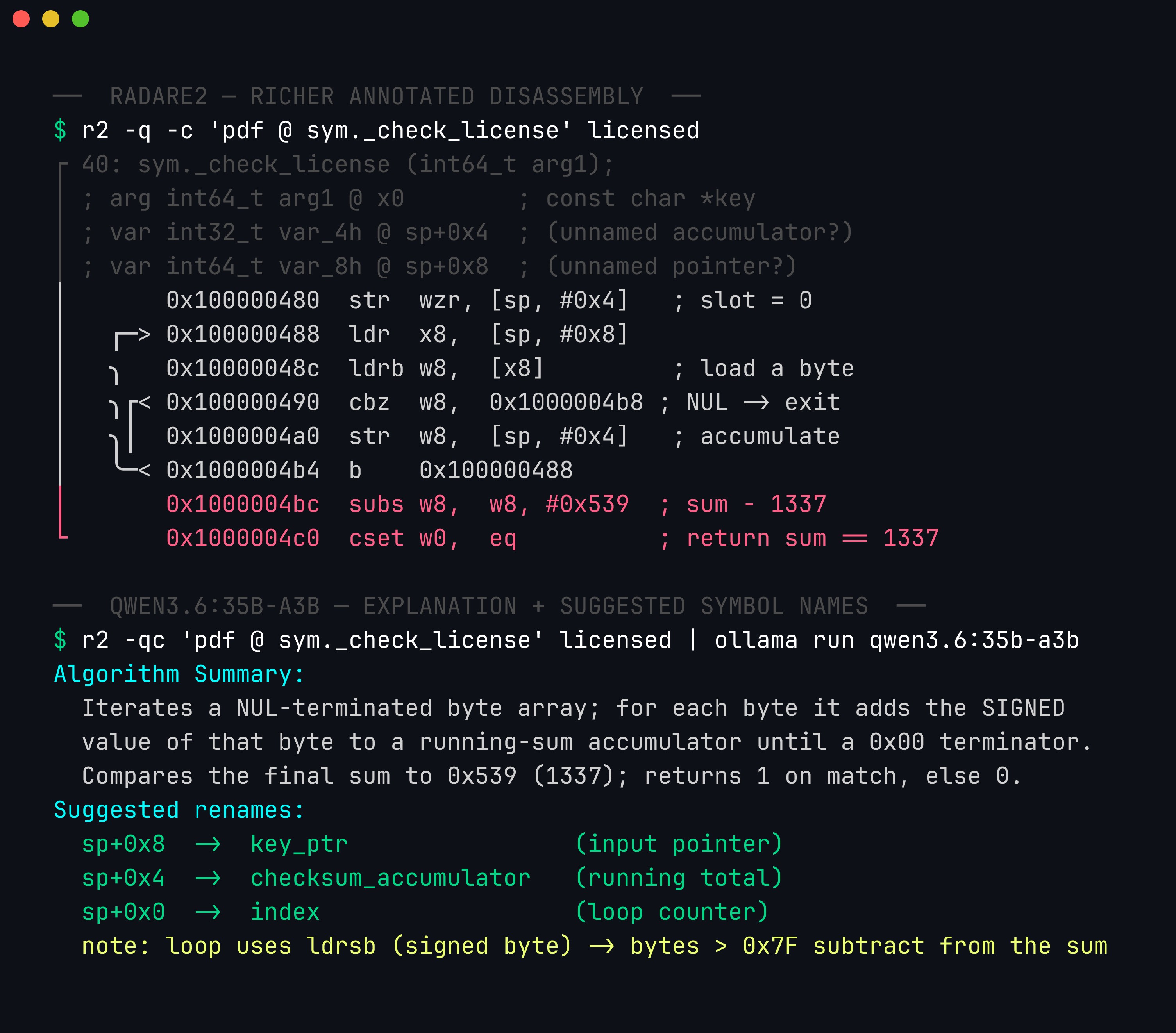
pdf gives the model a richer, pre-annotated view than raw objdump — labelled args, stack slots, and graph edges. The model reads that structure and returns not just an explanation but concrete rename suggestions you can apply with afn/afvn, turning var_4h into running_sum. It flags its own confidence — high here, because this is straight-line -O0 code — but that is a claim to test, not to trust.
Step 2: let a local LLM explain it
We feed the disassembly to qwen3.6:35b-a3b via Ollama and ask for a concise explanation:
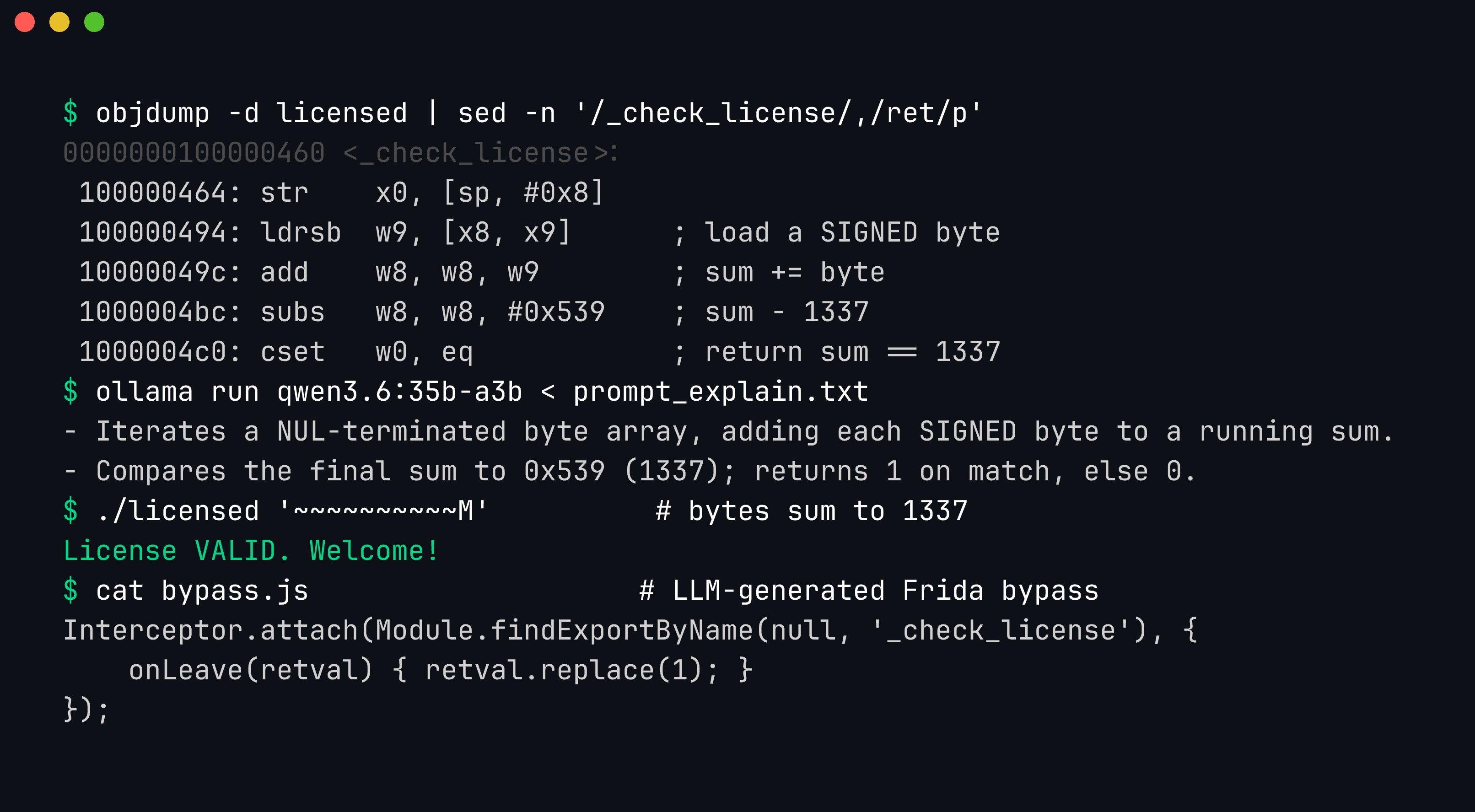
The full RE loop with a local model. objdump produces the ARM64 disassembly; qwen3.6:35b-a3b reads it and correctly explains that the function sums the signed byte values of the key and compares the total to 0x539 (1337); a forged key validates; and the model writes a Frida bypass.
The model’s analysis, verbatim, was:
Algorithm Summary
- Iterates through a byte array using an index counter; for each byte it adds the signed value of that byte to a running sum accumulator, continuing until it hits a
0x00terminator.- After the loop, it compares the final accumulated sum against the constant
0x539(1337 in decimal).- Returns
1if the sum equals0x539, and0otherwise — a simple checksum validation routine.Notes on Unclear Origins
- The loop uses
ldrsb(Load Register Signed Byte), so bytes with values > 127 are sign-extended and subtract from the sum. The magic number1337is an arbitrary checksum value chosen by the developer; its origin is not derivable from the code itself.
It also suggested concrete renames — sp+0x4 → checksum_accumulator, sp+0x8 → key_ptr, sp+0x0 → index. That is correct, and it took the model a couple of seconds versus a few minutes of human squinting. The ldrsb signed-byte observation is a genuinely sharp catch — a detail that is easy to miss skimming the loop. This is the honest value proposition of AI in RE: it is a fast, tireless junior analyst that produces a first-pass explanation you then verify — not an oracle you trust blindly.
Step 3: verify the analysis (trust, but verify)
An LLM explanation is a hypothesis. In RE you confirm hypotheses by making the program agree with you. If the model is right that any key whose bytes sum to 1337 is valid, we can forge one. ~ is ASCII 126; ten of them plus M (77) sum to 1260 + 77 = 1337:
$ ./licensed '~~~~~~~~~~M'
License VALID. Welcome!It validates. The model’s reverse engineering was correct, and we proved it empirically rather than taking its word — the discipline that separates useful AI-assisted RE from confident nonsense. (This matters: local models, especially smaller ones, will occasionally produce a plausible, fluent, and wrong explanation. Verification is not optional.)
Forging an input is the cheapest way to check a claim, but it is one of several. The general principle is to find a piece of ground truth the model never saw and confirm its story against it: forge an input that should pass (as here) or should fail; set a breakpoint or a Frida hook and read the register the model claims holds the sum; diff the model’s suggested C against a retdec/Ghidra decompilation of the same bytes; or simply re-run the prompt at temperature 0 and check the answer is stable. Contradiction between two independent readings is a red flag worth chasing. The loop below is the whole method in one picture.

The LLM’s output is a hypothesis, not a verdict. The red node is where careless workflows stop — accepting a fluent explanation as fact. A finding only earns the label once running code agrees with it: a forged key that validates, or a Frida trace of the live call returning what the model predicted.
Step 4: generate a Frida bypass
Recovering the algorithm is one outcome; in a real assessment you often just want to defeat the check to reach the functionality behind it. We ask the model for a Frida hook, and it produces the idiomatic bypass:
Interceptor.attach(Module.findExportByName(null, '_check_license'), {
onLeave: function (retval) {
retval.replace(1);
}
});Interceptor.attach leaves the original function in place but runs our callback around it; in onLeave we overwrite the return value with retval.replace(1), so every call reports a valid license regardless of what the checksum actually computed. Run against the live process (frida -f ./licensed -l bypass.js), the license gate is gone — no on-disk patching, no resigning. This is exactly the technique you use on real mobile apps to bypass jailbreak/root detection, certificate pinning, or license and subscription checks during an authorized assessment. (The model reached for the older Module.findExportByName; on current Frida you would write Module.getExportByName — a small, easily-verified drift that is a good reminder to read what the model emits before you run it.)
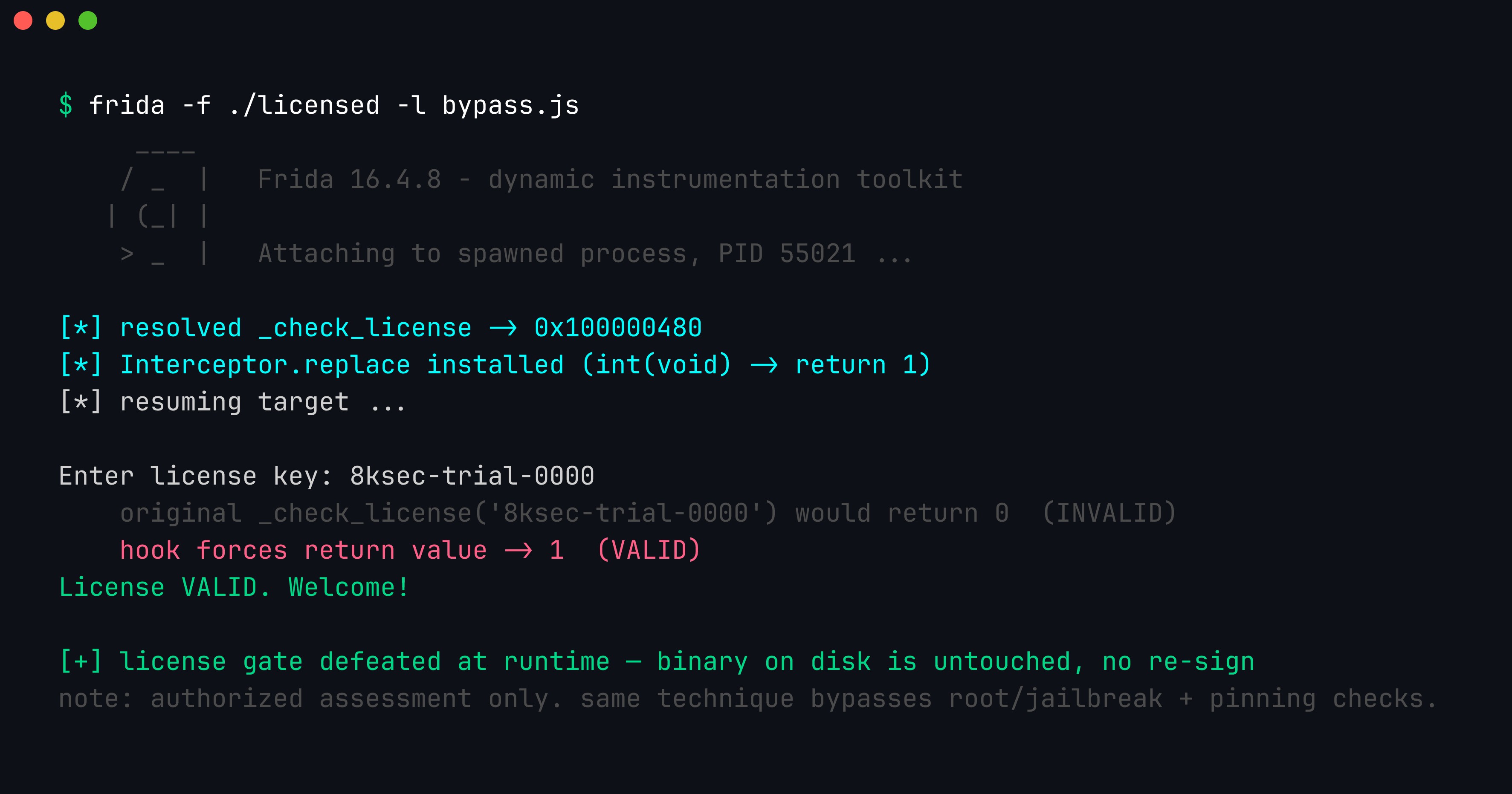
The bypass firing on the live process. frida -f spawns the target under instrumentation, resolves _check_license, and splices in the replacement; a deliberately-wrong key that would have returned 0 now returns 1 and the gate opens. The on-disk binary is never modified, so no code-signature is broken — which is why this works on a jailbroken device against a signed app.
Why local models specifically
You could paste that disassembly into a hosted chatbot and get a similar answer. For professional RE you often cannot, and should not:
- Confidentiality. The binary may be a client’s proprietary app under NDA, or malware you are not permitted to share. A local model keeps the artifact on your machine.
- Malware safety. Uploading live malware to a third-party service can violate handling agreements and tip off an adversary. Offline analysis avoids that entirely.
- Cost and scale. RE generates a lot of queries — every function, every rename, every “what does this do.” Local inference is free to run in a loop.
- Air-gapped labs. Serious malware analysis happens in isolated VMs with no internet. A local model is the only kind that works there.
The trade-off is quality: a 30B local model is very capable but not frontier-class, so verification (Step 3) matters more, not less. We cover model selection and the local-LLM setup in a dedicated post.
Scaling it up: from one function to a whole binary
The single-function demo generalises into a real workflow:
- Bulk explanation. Script your disassembler/decompiler (radare2’s
r2pipe, Ghidra’s headless mode, or Binary Ninja’s API) to extract every function, and pipe each to a local model for a one-paragraph summary and suggested name. You wake up to an annotated binary. - Guided triage. Ask the model to rank functions by “security relevance” — crypto, parsing, auth, IPC — so you spend your human attention where it counts.
- Hook generation. For each interesting function, have the model draft a Frida hook that logs arguments and return values, giving you instant dynamic visibility.
- Protocol and structure inference. Feed the model a function plus a few captured buffers and ask it to infer the wire format — a huge time-saver on custom protocols.
None of this replaces a reverse engineer. It compresses the tedious first 80% — reading boilerplate, renaming, summarising — so the human spends time on the 20% that is actually hard: the subtle logic bug, the exploitable primitive, the obfuscation that the model gets wrong.
Automating a whole binary (with code)
The single-function walkthrough is the “hello world.” The payoff is running the same loop over every function in a binary while you sleep. Two tools make this trivial to script: r2pipe (radare2’s scripting bridge, available for Python, Node, and more) and the Ollama HTTP API, which exposes your local model at http://localhost:11434. r2pipe drives the disassembler; Ollama runs the model; a short Python glue script ties them together.
The idea: open the binary, let radare2 analyse it (aaa discovers functions, cross-references, and strings), list every function as JSON, and for each one send its disassembly to the model asking for a one-paragraph summary and a suggested name. Then write the answer straight back into the radare2 project as a comment and a rename, so the annotations persist.
import r2pipe
import requests
import json
OLLAMA = "http://localhost:11434/api/generate"
MODEL = "qwen3.6:35b-a3b"
def ask_llm(prompt):
r = requests.post(OLLAMA, json={
"model": MODEL,
"prompt": prompt,
"stream": False,
"options": {"temperature": 0.1}, # low temp = less creative, more literal
}, timeout=300)
return r.json()["response"]
r2 = r2pipe.open("./target") # open the binary
r2.cmd("aaa") # analyse: functions, xrefs, strings
funcs = json.loads(r2.cmd("aflj")) # every function, as JSON
for f in funcs:
name, addr, size = f["name"], f["offset"], f["size"]
if size < 16: # skip thunks/stubs/PLT entries
continue
disasm = r2.cmd(f"pdf @ {addr}") # disassembly of this function
prompt = (
"You are a reverse engineer. Summarise this ARM64 function in ONE "
"paragraph and suggest a short snake_case name. Reply strictly as "
"JSON with keys 'summary' and 'name'.\n\n" + disasm
)
out = ask_llm(prompt)
try:
result = json.loads(out)
except json.JSONDecodeError: # model didn't return clean JSON
result = {"summary": out.strip().replace("\n", " "), "name": name}
# persist the annotation into the r2 project
r2.cmd(f"CCu base64:{__import__('base64').b64encode(result['summary'].encode()).decode()} @ {addr}")
r2.cmd(f"afn {result['name']} @ {addr}")
print(f"{name:40s} -> {result['name']}")
r2.cmd("Ps annotated") # save the project so renames/comments stick
r2.quit()A few practical notes. Set temperature low (0.1) — you want literal, deterministic readings of assembly, not creative prose. Skip tiny functions (size < 16); they are almost always compiler stubs and burn tokens for nothing. The CCu command attaches a user comment (base64-encoded so newlines and quotes survive), and afn renames the function; Ps annotated writes a radare2 project you can reopen later with everything intact. Ghidra users can do the same thing with headless mode — analyzeHeadless <project_dir> <project> -import target -postScript annotate.py — running a Jython/PyGhidra post-script that walks currentProgram.getFunctionManager().getFunctions(True) and calls the same Ollama endpoint.
This is the “wake up to an annotated binary” workflow. You kick the script off on a 4,000-function stripped binary before you log off; a 30B model at a few seconds per function chews through it overnight for free (no per-token API bill). In the morning you open the radare2 project and instead of fcn.100004a20 everywhere, you have parse_auth_token, aes_decrypt_block, verify_receipt_signature — a map of the binary. It will not all be right, but it does not need to be: it needs to be a good enough index that tells you which 20 functions to read carefully out of 4,000. Pair it with the triage step below and you have turned a week of orientation into an overnight batch job plus a morning of focused review.
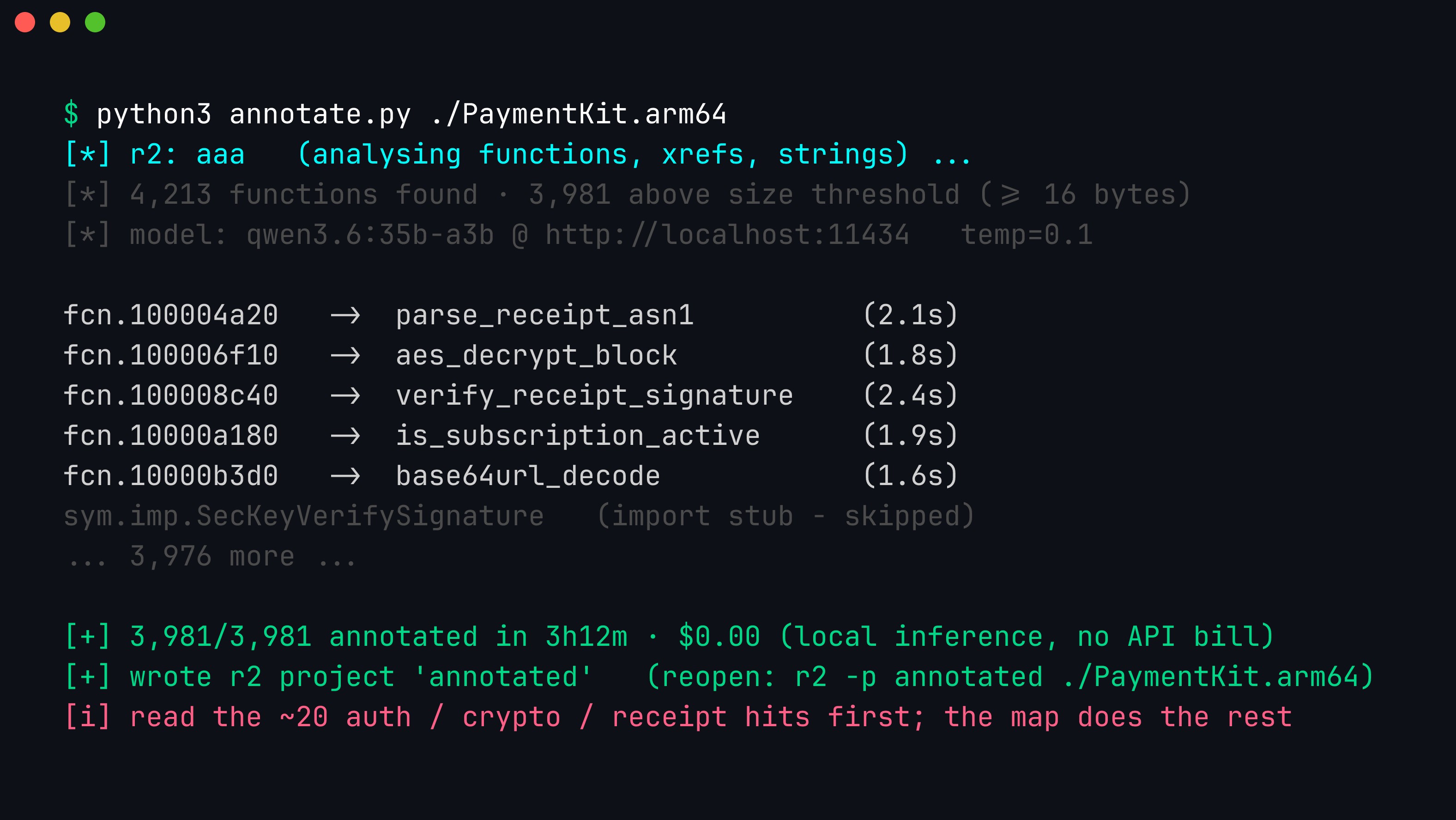
The batch loop in action. radare2’s aaa recovers ~4,000 functions; each one’s pdf is piped to the local model, which returns a suggested name written straight back with afn. Import stubs and sub-16-byte thunks are skipped to save tokens. Three hours and zero dollars later you reopen the saved project to a named map — and go straight to the ~20 auth/crypto/receipt functions that actually matter.
Decompiler + LLM beats disassembler + LLM
Everything above fed disassembly (raw ARM64) to the model. If your tool has a decompiler — Ghidra’s, Hex-Rays in IDA, or radare2’s pdc/pdg (the latter via the r2ghidra plugin) — feed the pseudo-C instead. It is a strict upgrade, for two reasons: context efficiency and accuracy.
Context efficiency. A function that is 60 lines of assembly is often 8–12 lines of pseudo-C. The decompiler has already done the hard structural work the model would otherwise have to reconstruct token by token: it recovered the loop, folded the stack-slot spills back into named locals, resolved the subs/cset idiom into ==, and turned branch targets into if/while/for. That means far fewer tokens per function, so more functions fit in the context window and each query is cheaper and faster — which matters enormously when you are looping over thousands of functions.
Accuracy. The model is vastly more fluent in C than in ARM64 assembly — its training corpus contains oceans of C and comparatively little annotated disassembly. Handing it pseudo-C plays to that strength. Compare the same license check. Raw assembly:
1000004a0: ldrb w8, [x9, x8]
1000004a4: ldr w10, [sp, #0x8]
1000004a8: add w8, w10, w8
1000004ac: str w8, [sp, #0x8]
1000004b0: ldr w8, [sp, #0xc]
1000004b4: add w8, w8, #0x1
1000004b8: str w8, [sp, #0xc]
1000004bc: b 0x100000488
...
1000004d0: subs w8, w8, #0x539
1000004d4: cset w0, eqVersus the decompiler’s pseudo-C for the same bytes:
int check_license(char *key) {
int sum = 0;
for (int i = 0; key[i] != 0; i++)
sum += key[i];
return sum == 0x539;
}Ask the model “what is 0x539 and how do I satisfy this check” against the second version and it answers correctly and instantly — the intent is right there. Against the first it has to first become a decompiler in its head, and small local models make more mistakes doing that: misattributing which stack slot is the counter versus the accumulator, or losing track of the loop back-edge (b 0x100000488). The general rule: let the specialised tool do the structural recovery, and let the LLM do the semantic naming and explanation. They are good at different halves of the job. Reserve raw-assembly prompting for the cases where the decompiler fails or produces obvious garbage — heavy obfuscation, hand-written assembly, or exotic instructions the decompiler models poorly.
Common pitfalls when using LLMs for RE
A few failure modes are worth knowing before you lean on this in a real engagement, because each has bitten people:
- Confident hallucination. The model will sometimes produce a fluent, authoritative, wrong explanation — inventing a purpose for a function, or misreading a comparison. This is most dangerous when the answer is plausible. Always confirm empirically (as we did by forging a key); never ship a finding on the model’s word alone.
- Context-window limits. A large function, or a whole binary’s disassembly, may not fit in the model’s context. You will need to chunk — per-function, or per-basic-block — and the model loses the cross-function view. Decompiler output (pseudo-C) is far more context-efficient than raw assembly, so prefer it when available.
- Optimized and obfuscated code. LLMs do well on
-O0, straight-line code like our example. Heavily optimized code (inlining, vectorization, register juggling) or deliberately obfuscated code (control-flow flattening, opaque predicates, string encryption) degrades their accuracy sharply — exactly the code you most want help with. - Register/ABI confusion. Small models occasionally mix up calling conventions or misattribute which register holds an argument. Cross-check anything security-critical against the actual ABI.
- Over-trusting generated hooks. An LLM-written Frida hook can have the wrong signature, hook the wrong export, or crash the target. Treat generated instrumentation as a draft you test in a controlled environment, not as ground truth.
None of these are reasons to avoid the technique — they are reasons to keep a human reverse engineer in the loop. The model accelerates the mechanical parts; your judgement stays responsible for the conclusions.
Apple-platform specifics: iOS RE with an LLM
Our lab used a standalone Mach-O binary to keep the moving parts minimal. Real iOS reversing has extra structure that you must handle before the LLM sees anything useful — and, happily, some of that structure is exactly where an LLM shines.
The dyld shared cache. On modern iOS and macOS, Apple does not ship the system frameworks (UIKit, Foundation, Security, and hundreds more) as separate .dylib files. They are pre-linked and merged into one enormous blob, the dyld shared cache, that lives at /System/Library/dyld/ on device. If you try to disassemble an app that calls UIKit functions, the calls point into the cache, not into files you have. So the first step is extraction: split the cache back into individual framework images. Tools like ipsw (ipsw dyld extract), the dyld_shared_cache_util utility, or Ghidra’s dyld-cache loader do this. Only after extraction can your disassembler resolve a branch to -[NSURLSession dataTaskWithRequest:] instead of a bare address. Skip this step and half your cross-references dead-end into the void.
Objective-C metadata and class-dump. Objective-C is a gift to reverse engineers. Because method dispatch goes through objc_msgSend at runtime, the compiler must keep the class names, method names (selectors), and protocol layouts in the binary as strings, stored in __objc_classlist, __objc_selrefs, and friends. Tools like class-dump (and its forks) parse this metadata and reconstruct the header files — you get @interface PaymentManager with methods like -verifyReceipt:withSignature: for free, without reading a single instruction. This is where the LLM earns its keep: feed it a class’s dumped interface plus a couple of method bodies and ask “what does this class do and which methods are security-relevant,” and it reads the selectors like documentation. A selector named -[LicenseValidator isProKey:] tells the model (and you) more than any amount of assembly.
Swift name mangling. Swift is harder. Its symbols are mangled — _$s4Demo11LicenseCheckV6verifySbSS_tF encodes the module, type, method, and signature in a compact scheme. Run these through swift-demangle (ships with the toolchain) first: that string becomes Demo.LicenseCheck.verify(_: Swift.String) -> Swift.Bool. Demangle before prompting; a small local model will often guess wrong on raw mangled names but reads the demangled signature perfectly. Swift also lacks the rich runtime metadata of Objective-C, so you lean harder on the decompiler and on the LLM to recover intent from control flow.
The mobile-specific takeaway: the LLM is most valuable at recovering intent from names — selectors, demangled Swift symbols, and dumped class layouts — which is precisely the layer Apple’s runtimes preserve in the binary. Do the platform plumbing (extract the cache, class-dump, demangle) first, then let the model summarise the human-readable surface.
Frida in depth
The bypass in Step 4 used Interceptor.replace, the bluntest tool Frida offers: it discards the original function entirely and substitutes yours. That is perfect for “make this check always pass,” but most dynamic analysis wants the opposite — to observe a function without changing its behaviour. That is Interceptor.attach.
Interceptor.attach installs two optional callbacks around the original: onEnter, which runs before the function with access to its arguments (args[0], args[1], …), and onLeave, which runs after with the return value (retval). You can read arguments, dump the memory they point to, and even rewrite the return — all while the real function still runs:
Interceptor.attach(Module.getExportByName(null, '_check_license'), {
onEnter(args) {
// args[0] is the `const char *key` pointer
this.key = args[0];
console.log('[check_license] key =', this.key.readUtf8String());
// dump the first 32 bytes of whatever it points at
console.log(hexdump(this.key, { length: 32, ansi: true }));
},
onLeave(retval) {
console.log('[check_license] returned', retval.toInt32());
// uncomment to force success without replacing the function:
// retval.replace(1);
}
});That single hook gives you a live trace of every call: the key that was passed, a hexdump of the surrounding memory, and the verdict — invaluable for understanding how an app uses a function before you decide how to defeat it. readUtf8String(), readByteArray(), and hexdump() cover most data you will want to inspect; for structs you index off the pointer with .add(offset).readU32() and friends. Use attach to understand, replace to override.
For code with no clear function boundary — a giant obfuscated blob, or a virtual-machine interpreter — reach for Stalker, Frida’s code-tracing engine. Stalker.follow() traces every basic block a thread executes, letting you see which paths actually run for a given input. It is heavier and noisier than Interceptor, but it is the tool when you do not yet know which function to hook.
This is another place the LLM slots in. Given a recovered function signature — from class-dump, from the decompiler, or from your own analysis — ask the model to write the hook: “generate a Frida Interceptor.attach for -[PaymentManager verifyReceipt:withSignature:] that logs both NSString arguments and the BOOL return value.” It knows the Objective-C argument layout (args[0] = self, args[1] = _cmd, args[2] = first real argument) and the ObjC-to-Frida idioms (ObjC.Object(args[2]).toString()), and drafts a working hook in seconds. As always, treat it as a draft: run it against a controlled target, confirm the argument indices, and fix the inevitable off-by-one in a selector’s argument slot before you trust its output.
![JavaScript: an LLM-drafted Frida Interceptor.attach on -[ReceiptValidator validate:], with onEnter reading args[2] as the receipt NSData via ObjC.Object and hexdumping it, and onLeave reading the BOOL return in x0/w0 with a commented-out retval.replace(ptr(1)) to force success](/images/blog/ai-ss-reveng-attach-hook.jpg)
The model drafts the idiomatic hook: it correctly skips args[0]/args[1] (self and _cmd) to reach the real argument at args[2], wraps it with ObjC.Object, and reads the BOOL return from x0/w0 in onLeave. The commented retval.replace(ptr(1)) is the one-line pivot from observe to override. It is a starting point, not gospel — the // DRAFT line is a reminder to confirm the selector’s argument indices against the running app before you rely on the trace.
Handling obfuscation and optimization
The honest limit of this whole approach is that LLMs are strongest on exactly the code that needs the least help — clean, -O0, straight-line functions like our lab — and weakest on the code you most want assistance with. It is worth knowing why they degrade, so you can plan around it.
- Control-flow flattening replaces natural
if/whilestructure with a single dispatch loop driven by a state variable, so the real order of operations is hidden behind aswitch. The decompiler produces a spaghettiwhile(1) switch(state)and the model loses the thread — the linear narrative it relies on is gone by construction. - Opaque predicates inject branches whose outcome is constant but not obviously so (
if ((x*x - x) % 2 == 0)is always true). The model treats them as real logic and reasons about dead paths, polluting its explanation with conditions that never fire. - String encryption hides the constants that give a function away. Our license check was easy partly because
0x539and the"License VALID"string were in plain sight. Encrypt the strings and decrypt them at runtime, and static analysis — human or model — sees only opaque byte arrays and a decryption stub. - Heavy optimization (
-O2/-O3) inlines callees (so one function is secretly five), vectorizes loops into SIMD (ld1/st1over NEON registers that no longer map cleanly to a scalar loop), and juggles registers aggressively. The clean source-to-assembly correspondence the model leans on erodes.
Pragmatic tactics: deobfuscate first. Run a string-decryption pass (often a Frida hook on the decrypt routine that dumps plaintext, or an emulation pass with something like Unicorn) and feed the model the recovered strings. For flattening, use a deflattening tool or script before decompiling. Work on smaller slices — a single basic block or a de-inlined helper is more tractable than a 2,000-instruction flattened monster; give the model the piece, not the whole. Cross-check relentlessly: an explanation of obfuscated code is a weaker hypothesis than usual, so confirm it dynamically (hook it, watch it run) before believing it. And accept the division of labour: obfuscation is where the human reverse engineer still clearly beats the model, so spend your expensive attention there and let the LLM handle the clean code around it.
A realistic end-to-end workflow
Pulling the threads together, here is how the pieces compose on a genuine mobile assessment: an unknown iOS app binary, and a question like “how does this app decide the user is a paying subscriber, and can I defeat that check?”
- Platform plumbing. Extract the app’s Mach-O, and if it references system frameworks, extract the relevant images from the dyld shared cache. Run class-dump to recover the Objective-C class list; demangle any Swift symbols. You now have a rough map of named classes and methods.
- Triage by relevance. Run the batch script from earlier over every function, but bias the prompt toward the question: ask the model to flag anything touching “subscription, receipt, entitlement, license, or purchase.” Out of thousands of functions it surfaces a shortlist —
-[ReceiptValidator validate:],SKPaymentQueueobservers, aisSubscribedaccessor. This is the model doing what it is best at: fast, cheap, first-pass triage over a haystack. - Decompile and explain the shortlist. For each flagged function, feed the decompiler’s pseudo-C (not raw assembly) to the model and ask for a precise explanation of the logic and the conditions under which it returns “subscribed.” Now you are reading 10 functions carefully instead of 3,000 blindly.
- Form a hypothesis. Say the model concludes: “
-[ReceiptValidator validate:]returns aBOOL;isSubscribedgates the premium UI on that return value.” That is a testable claim, not a conclusion. - Generate hooks for dynamic confirmation. Ask the model to write a Frida
Interceptor.attachthat logs the arguments and return ofvalidate:andisSubscribed. Run it against the live app and watch: doesisSubscribedreally return0for your free account, and is it really downstream ofvalidate:? The trace confirms or kills the hypothesis. - Defeat and verify empirically. If confirmed, switch the hook from
attachto aretval.replace(1)(orInterceptor.replacereturning1) and observe the premium features unlock. The proof is behavioural — the app itself agrees with your analysis — exactly the discipline from Step 3 of the lab, now applied to a real target.
Notice the shape: the LLM compresses the two most tedious phases — orientation over a huge binary, and drafting instrumentation — while every conclusion is nailed down by running code and watching what the app does. That is the sustainable way to fold AI into mobile security testing: fast machine triage, human judgement on the security logic, and empirical verification on the device before anything goes in a report.
Key takeaways
- Reverse engineering is largely pattern recognition and summarisation, which is why a local LLM is a genuinely useful “junior analyst” for explaining disassembly and recovering intent.
- Use a local, offline model for RE because binaries are frequently confidential, malicious, or under NDA — and because RE generates far too many queries to send to a paid API.
- Trust, but verify. An LLM explanation is a hypothesis; confirm it empirically (we forged a key that validated). Smaller local models will occasionally be fluent and wrong.
- The model can also act: it generated a correct Frida
Interceptor.replacehook that bypasses the license check on the live process, the same technique used against real app protections. - The workflow scales — bulk-explain every function, triage by relevance, auto-generate hooks — compressing the tedious 80% of RE so you spend time on the hard 20%.
Conclusion
A local open-source LLM will not reverse a binary for you, but it will make you meaningfully faster at the parts of RE that are mechanical, and it will do so privately and at scale. Paired with objdump/radare2 for static analysis and Frida for dynamic instrumentation, it is a practical upgrade to any mobile-security or malware-analysis workflow — which is exactly how we teach it in Advanced AI Security and our mobile security trainings.
References
- radare2 — Unix-like reverse engineering framework. https://github.com/radareorg/radare2
- Frida — Dynamic instrumentation toolkit. https://frida.re/
- NCC Group / community — Ghidra + LLM plugins (e.g., GhidrOllama, Gepetto for IDA). https://github.com/JusticeRage/Gepetto
- Ollama — Run open-source LLMs locally. https://ollama.com/
- Apple — ARM64 (AArch64) procedure call standard. https://github.com/ARM-software/abi-aa
- Trail of Bits — Using LLMs to assist reverse engineering. https://blog.trailofbits.com/
- r2pipe — Scripting radare2 from Python/Node. https://github.com/radareorg/radare2-r2pipe
- Ollama — REST API reference. https://github.com/ollama/ollama/blob/main/docs/api.md
- NSA — Ghidra (headless
analyzeHeadlessmode). https://github.com/NationalSecurityAgency/ghidra - class-dump — Generate Objective-C headers from Mach-O. https://github.com/nygard/class-dump
- blacktop — ipsw: iOS/macOS research toolkit (dyld shared cache extraction). https://github.com/blacktop/ipsw
- Frida — Interceptor and Stalker API reference. https://frida.re/docs/javascript-api/
Get in Touch
Want to learn these techniques hands-on, or need help assessing your own mobile or AI stack? We run live and on-demand trainings, offer mobile-security certifications, and take on penetration-testing engagements. Pick the door that fits.
We respond within one business day. Visit our events page to see where we'll be next.


