AI-Assisted Fuzzing: Generating Harnesses with a Local LLM
Introduction
Fuzzing is one of the most productive bug-finding techniques ever invented. It found a huge fraction of the memory-corruption CVEs in browsers, media parsers, and OS kernels. But it has a friction point that keeps a lot of engineers away from it: writing the harness. Before a fuzzer can throw millions of inputs at your code, someone has to write the small piece of glue, the harness, that takes a blob of bytes and feeds it into the function under test in a sensible way.
That glue is exactly the kind of small, well-specified, boilerplate-heavy code that today’s language models are good at. In this post we use a local, open-source LLM running offline via Ollama to generate a libFuzzer harness for a C library, compile it with AddressSanitizer, and catch a real stack-buffer-overflow, all reproducible on your own machine. It is a small worked example of a bigger theme in the Advanced AI Security course: using AI as a force multiplier for offensive security work, going beyond the usual framing of it as something to defend against.
This post is written to be readable by someone who has never fuzzed before and useful to someone who fuzzes for a living. If you already know what a harness and a sanitizer are, skim the primer and jump to the lab.
📦 Download the lab:
ai-fuzzing-lab.zipcontains the vulnerable target, the LLM prompt, the generated harness, and an ASAN driver. It runs on stock macOS or Linux with clang. For authorized testing and education only.
Primer: what is fuzzing, actually? (for beginners)
If you are new to this, here are the four ideas you need. Everyone else can skip ahead.
- Fuzzing is automated testing that feeds a program a flood of malformed, random, or mutated inputs and watches for crashes. A crash on attacker-controllable input is very often a security bug.
- Coverage-guided fuzzing, the modern kind used by libFuzzer and AFL++, is smarter than random: the fuzzer instruments your code, notices when a new input reaches a new code path, and keeps that input as a seed to mutate further. Over time it “learns” the input format well enough to reach deep, rarely-executed code.
- A harness is the entry point the fuzzer calls. For libFuzzer it is a single function,
LLVMFuzzerTestOneInput(const uint8_t *data, size_t size), whose job is to turn the raw bytes the fuzzer generated into a call to the function you actually want to test. - A sanitizer is a compiler feature that makes bugs loud. AddressSanitizer (ASan) instruments every memory access and aborts with a detailed report the instant your program reads or writes out of bounds, turning a silent, maybe-exploitable corruption into an immediate, precise stack trace. Without a sanitizer, many overflows do not crash at all and you would never notice the fuzzer found one.
The reason harness-writing is a bottleneck is that it is per-target toil: each library and entry point needs its own bespoke glue. That repetitiveness is precisely what makes it a good fit for an LLM.
Where the LLM helps (and where it doesn’t)
The division of labour matters here, because “AI finds bugs” is a claim worth scrutinising.
The fuzzer finds the bug. Coverage-guided mutation exploring millions of inputs is doing the actual discovery, and AddressSanitizer is doing the detection. Neither of those is AI.
The LLM removes the friction that stops people from fuzzing in the first place. It is good at:
- Reading a function signature or a header and writing a syntactically correct harness that calls it properly.
- Handling structured inputs. It splits the fuzzer’s byte blob into the fields a function expects, such as a length, a type tag, and a payload, so more inputs are “valid enough” to reach interesting code.
- Suggesting a seed corpus and a dictionary of magic bytes and keywords that help the fuzzer get past
if (memcmp(data, "FUZZ", 4))-style gates. - Scaling this across a large codebase, generating a first-draft harness for dozens of entry points far faster than a human would.
It is not good at guaranteeing the harness is correct or meaningful, and a subtly wrong harness can waste enormous CPU or, worse, give false confidence. So the workflow is generate, then review: you still read the harness the model wrote. Google’s OSS-Fuzz team published the same pattern in their OSS-Fuzz-Gen work. LLM-generated harnesses improved coverage across 272 C/C++ projects, adding over 370,000 lines of newly-covered code and up to +29% line coverage over the existing human-written harnesses, and they surfaced real, previously-unreachable bugs on mature, heavily-fuzzed code.
The target: a length-prefixed record parser
Parsers are the classic fuzzing target, because they take untrusted bytes and make decisions based on their contents. Our lab ships a tiny one with a deliberate, realistic bug:
/* target.c - parse [1 byte type][1 byte length][length bytes value] ... */
int parse_records(const uint8_t *data, size_t size) {
size_t off = 0;
int checksum = 0;
while (off + 2 <= size) {
uint8_t type = data[off];
uint8_t len = data[off + 1];
char value[16];
memcpy(value, data + off + 2, len); /* BUG: len may exceed 16 */
for (uint8_t i = 0; i < len; i++) /* use `value` so it stays live */
checksum += value[i] ^ type;
off += 2 + len;
}
return checksum;
}The bug is textbook and extremely common in the wild: an attacker-controlled length field, len, is used to memcpy into a fixed 16-byte stack buffer with no bounds check. Because len is a full byte, it can be as large as 255, so any record whose len exceeds 16 smashes the stack. This is the shape of countless real CVEs in TLV parsers, image decoders, and network protocol handlers.
A note for beginners on why the loop is there: we deliberately read from
valueafterward. If the buffer were written but never read, an optimizing compiler would delete thememcpyas a “dead store” and the bug would vanish at-O1. This is a genuinely useful lesson: compiler optimization can hide bugs from a naive harness, which is one reason you fuzz at the optimization level you ship.
Generating the harness with a local model
Now the AI part. We run everything through Ollama with qwen3.6:35b-a3b, an open-weights code model, entirely offline. Why local? Keeping the target source on your own machine matters when it is a client’s proprietary code under NDA, and running offline means no per-token costs when you generate harnesses for hundreds of functions. It also works inside an air-gapped analysis VM. We’ll cover the local LLM setup in depth in an upcoming blog.
The prompt is deliberately tight: we want only the harness, no prose:
You are a fuzzing expert. Write a libFuzzer harness for the C function below.
Output ONLY C code: an LLVMFuzzerTestOneInput(const uint8_t *data, size_t size)
that forwards the input to parse_records. Include the extern declaration.
Keep it minimal. No explanation.
int parse_records(const uint8_t *data, size_t size);The model returns exactly what we want:
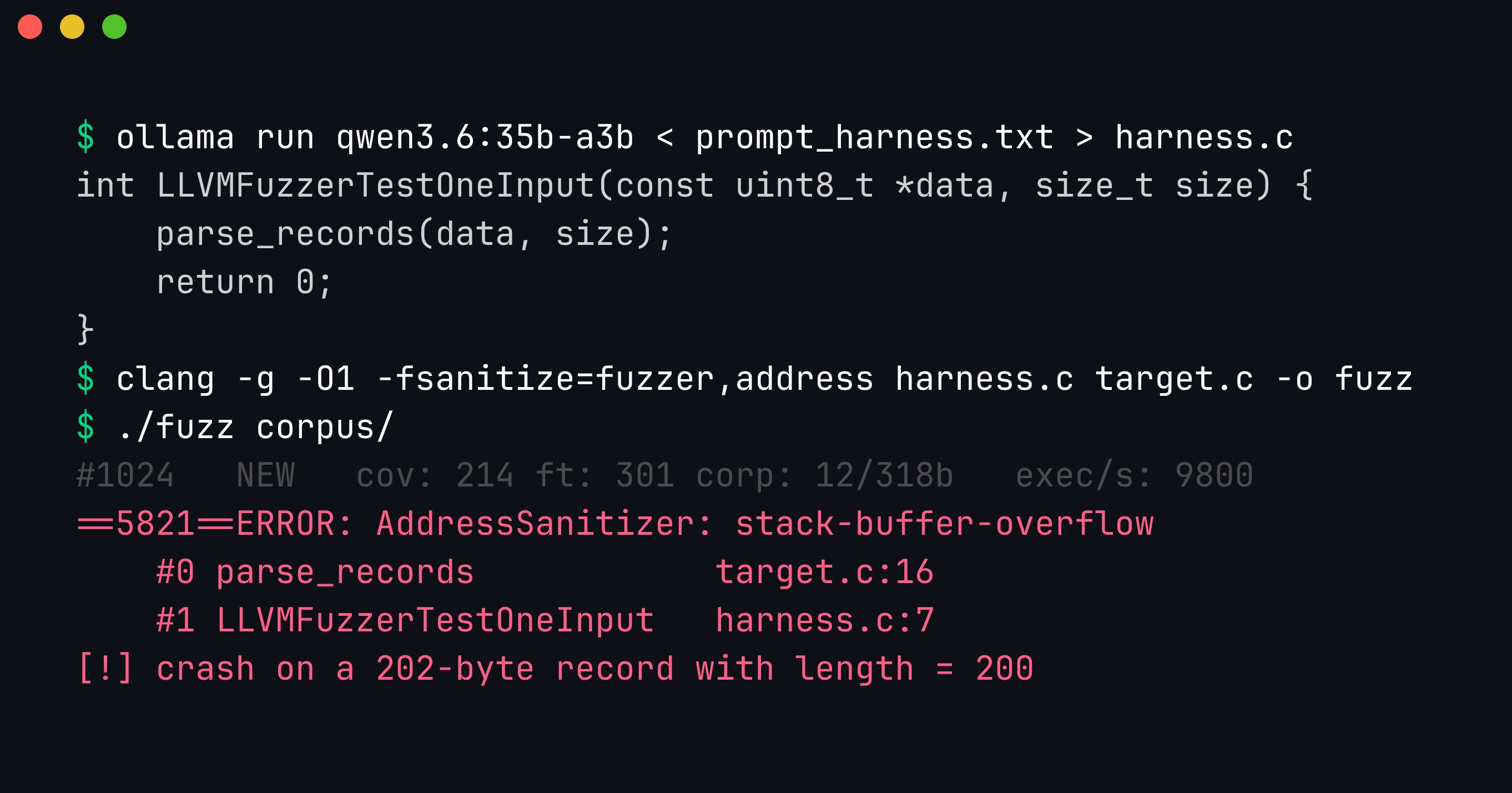
The full pipeline, start to finish. The local model generates a correct LLVMFuzzerTestOneInput that forwards the fuzzer’s bytes to parse_records; clang compiles it with AddressSanitizer; and running it on a 202-byte record with length = 200 produces a real stack-buffer-overflow report, traced through LLVMFuzzerTestOneInput (harness.c:7) into parse_records (target.c:16).
The generated harness is the minimal, correct thing:
#include <stdint.h>
#include <stddef.h>
extern int parse_records(const uint8_t *data, size_t size);
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
parse_records(data, size);
return 0;
}For a target this simple, forwarding the bytes directly is the right harness. The LLM earns its keep on structured inputs, where you want it to, say, carve the first 4 bytes as a header, use the next 2 as a length, and pass the rest as a body. That is where the boilerplate multiplies and where a human’s attention runs out across a big codebase.
Reviewing the generated harness (guarding against hallucination)
Before you compile anything the model wrote, read it against a short checklist. A good harness, and the properties a hallucinated one violates, comes down to a handful of invariants:
- It calls the real API. The most common LLM failure is inventing a plausible-but-nonexistent function or the wrong signature, such as
parse_records(buf, &len)when the target takes(data, size). This is cheap to catch: it simply fails to compile or link. Grep the header for the exact symbol before trusting it. - It is a pure function of the input bytes. No global state carried across calls, no reliance on the clock or a random seed, no network or filesystem I/O. libFuzzer calls the harness millions of times in one process, as we cover below, so any leaked state or non-determinism poisons reproducibility and coverage.
- The harness itself is memory-safe. It must be stricter with lengths than the target: if the harness over-reads the fuzzer’s buffer, ASan flags your glue instead of the bug. Every index into
datamust be gated bysize. - It actually reaches the target. A harness that compiles but sizes its input wrong, or exits early on most inputs, will fuzz nothing. The only ground truth here is coverage: confirm the target function is being executed, don’t assume it.
The discipline is the same throughout AI-assisted security: the model drafts, and a hallucinated harness is a wrong harness. It either won’t compile, which is harmless, or, worse, it fuzzes the wrong thing and hands you false confidence. Reading it takes a minute; a silently-wrong harness wastes CPU-days.
Compiling and catching the bug
Apple’s stock clang does not ship the libFuzzer runtime, so the lab includes a tiny standalone ASAN driver that reads a file and calls the harness, so the exact same LLVMFuzzerTestOneInput runs on plain macOS. On Linux, or with Homebrew LLVM, compile with -fsanitize=fuzzer,address instead for true coverage-guided fuzzing.
clang -g -O1 -fsanitize=address target.c harness.c driver.c -o fuzz_target
# a benign record: type=1, len=2, "AB" -> processed cleanly
python3 -c "import sys;sys.stdout.buffer.write(bytes([1,2,65,66]))" > seed_ok
./fuzz_target seed_ok # [ok] input of 4 bytes processed with no crash
# a malicious record: type=1, len=200, then 200 bytes -> overflow of value[16]
python3 -c "import sys;sys.stdout.buffer.write(bytes([1,200])+b'A'*200)" > crash
./fuzz_target crash # AddressSanitizer abortsThe crash report is worth reading line by line:
==ERROR: AddressSanitizer: stack-buffer-overflow ...
WRITE of size 200 at 0x... thread T0
#0 __asan_memcpy
#1 parse_records target.c:16
#2 LLVMFuzzerTestOneInput harness.c:7
#3 main driver.c:10
...
This frame has 1 object(s):
[32, 48) 'value' (line 15) <== Memory access ... overflows this variableEvery line here is signal: it is a WRITE, not a read, of size 200, in parse_records at line 16, our memcpy, reached through the LLM-generated harness, and ASan even names the overflown variable as value, the 16-byte buffer. That is a complete, actionable bug report a developer can fix in minutes.
From crash to root cause to fix
The value of a good sanitizer report is that it collapses the distance between “it crashed” and “here is the line to change.” Read the trace top-down: frame #1 parse_records target.c:16 is the faulting instruction, and the object note, 'value' (line 15), names the buffer that was overrun. So the root cause is unambiguous: len is attacker-controlled, up to 255, and value is 16 bytes, so the memcpy writes past the buffer whenever len > 16. The fix is one clamp for the write and one bounds check so we never read past the input either:
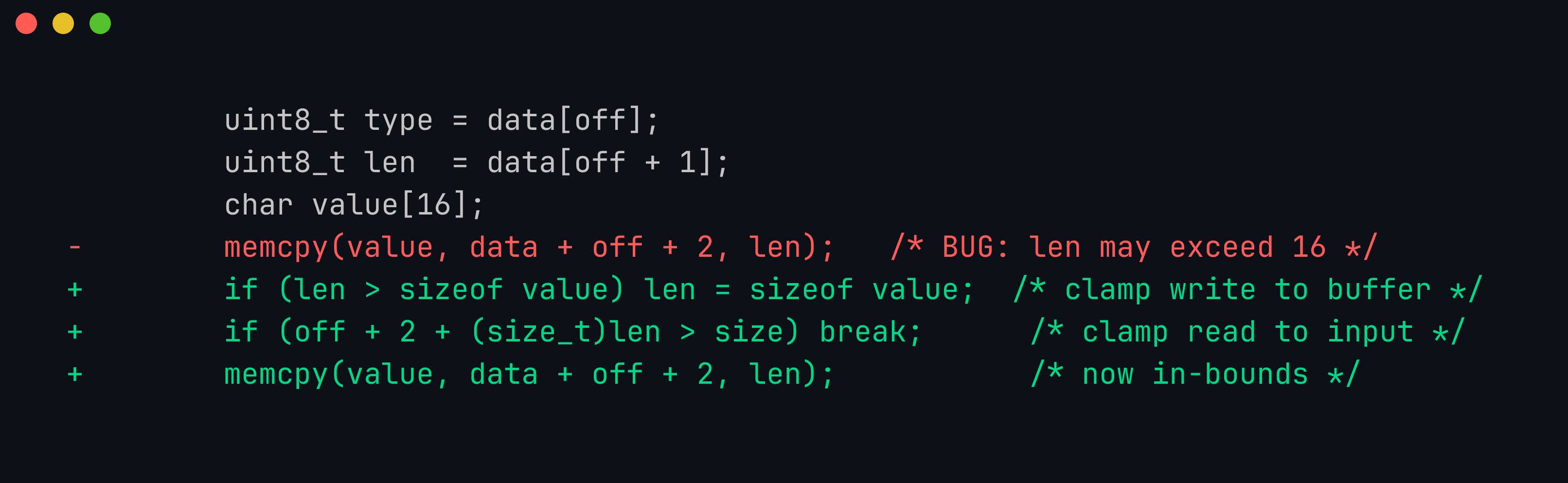
From ASan report to patch: len is clamped to the size of value so the copy can never overflow the 16-byte buffer, and off + 2 + len is checked against size so the parser never reads past the fuzzer’s input. The clamp fixes the reported WRITE; the second guard closes the sibling out-of-bounds READ that the same missing-length-check pattern would otherwise expose.
Two habits are worth forming here. First, fix the whole bug class rather than the single input. The reproducer had len = 200, but the real defect is an unvalidated length used as a copy size, so the patch must hold for every len. Second, re-fuzz after the fix: rebuild with the same ASan harness, replay the saved crash to confirm it no longer aborts, then let the fuzzer keep running on the accumulated corpus to make sure the patch did not just move the overflow one field over. Until you have re-fuzzed it, a fix is only a hypothesis.
Going further: seeds, dictionaries, and structure-aware fuzzing
The toy above crashes on the first bad input. Real targets hide their bugs behind format checks, and this is where an LLM-assisted workflow really pays off:
- Seed corpus. A fuzzer starting from random bytes may never produce a valid file header. Ask the model to generate a handful of minimal valid inputs, such as a valid PNG or a valid record, to seed the corpus, and the fuzzer starts from “almost valid” and mutates outward.
- Dictionaries. libFuzzer accepts a
-dict=file of interesting tokens such as magic bytes, keywords, and chunk names. An LLM that has read the spec can produce that dictionary, helping the fuzzer blow pastif (magic != 0x89504E47)gates it would otherwise take billions of iterations to guess. - Structure-aware harnesses. For inputs with checksums or length fields, a naive harness wastes most of its inputs failing an early integrity check. Prompt the model to write a harness that repairs the structure, recomputing the checksum and fixing the length, before calling the target, so mutations land on the parsing logic you actually care about. This is the single biggest lever on fuzzing throughput for structured formats.
- Coverage feedback loop. The most advanced version, and an active research direction in OSS-Fuzz and Google’s own work, closes the loop: run the fuzzer, feed the coverage report back to the LLM, and ask it to write a better harness or new seeds targeting the uncovered branches.
Coverage-guided fuzzing internals
We keep saying “coverage-guided,” so here is what that actually means. Understanding how the fuzzer measures progress is what lets you tell a good harness from a wasteful one.
When you compile with -fsanitize=fuzzer, the compiler does something clever: it inserts a tiny callback at every edge in the control-flow graph. An edge is a transition between two basic blocks. Think of each if or loop as splitting execution into branches, where each branch taken is an edge. The instrumentation maintains a big table, the coverage map, in shared memory; each time execution crosses an edge, the corresponding counter is bumped. AFL++ uses the same idea with an 8-bit-per-edge bitmap and “hit count buckets” that record whether an edge was hit once, 2–3 times, 4–7, or 8–15, so it distinguishes “we entered the loop once” from “we entered it a thousand times.”
Here is the loop the fuzzer actually runs, in pseudo-code:
corpus = [initial seeds]
while running:
input = pick_from(corpus) # favour small, fast, high-coverage inputs
mutant = mutate(input) # flip bits, splice, insert dict tokens…
reset_coverage_map()
run_harness(mutant) # execute LLVMFuzzerTestOneInput
if coverage_map has any NEW edge:
corpus.add(mutant) # this input is "interesting" — keep it
if crash_or_sanitizer_abort:
save(mutant); report()The line that matters is if coverage_map has any NEW edge, and everything else follows from it. A purely random fuzzer generates a mutant, runs it, learns nothing, and throws it away. A coverage-guided fuzzer keeps any mutant that reached code no previous input reached, and then mutates that further. The corpus therefore behaves like an evolving population of inputs rather than a fixed list of test cases; each one is a stepping stone that unlocked a new region of the program. Reaching a deep function often requires passing through ten nested if statements; random bytes have essentially zero chance of satisfying all ten at once, but coverage feedback lets the fuzzer solve them one at a time, saving the input that cracked each gate.
This is why coverage guidance beats blind random testing by orders of magnitude, not a few percent. Consider a 4-byte magic check, if (memcmp(data, "\x89PNG", 4) == 0). Blind fuzzing has a one-in-four-billion chance, 2^32, of guessing those exact four bytes. A coverage-guided fuzzer, the moment a mutation gets even the first byte right and that changes which branch is taken, records progress and builds on it, turning an astronomically unlikely event into a short walk. Add a dictionary, covered below, and it is near-instant.
A few practical consequences fall out of this model, and they directly shape how you should have the LLM write harnesses:
- Fast harnesses fuzz more. Coverage is measured per execution, so executions-per-second is the number that matters. libFuzzer runs in-process: the harness is called millions of times in one long-lived process, with no
fork/execper input, which is why it hits tens of thousands of execs/sec. AFL++ traditionally forks a fresh process per input, which is robust against state corruption but slightly slower, and mitigates it with a fork server and persistent mode, its equivalent of the in-process loop. - Global state breaks it. Because libFuzzer reuses the process, a harness that leaks memory or leaves global state dirty across calls will drift and produce non-reproducible results. A good harness is a pure function of its input bytes.
- Non-determinism poisons the signal. If the code path depends on the clock, a random seed, or thread scheduling, the coverage map becomes noisy and the fuzzer chases phantom “new” edges. Pin those sources of entropy in the harness.
| libFuzzer | AFL++ | |
|---|---|---|
| Execution model | In-process, one process, millions of calls | Fork server / persistent mode |
| Instrumentation | LLVM SanitizerCoverage (compile-time) | Compile-time (afl-clang-fast) or QEMU/Frida for binaries |
| Coverage granularity | Edge coverage, -fsanitize=fuzzer | Edge coverage + hit-count buckets |
| Best when | You have source and a library API | You have source or only a binary; whole-program targets |
| Corpus/dict format | -dict=, corpus directory | -x dict, -i input_dir |
Both consume the same corpus and the same dictionaries, and both are happy to run the same LLVMFuzzerTestOneInput, because AFL++ ships a libFuzzer-compatibility driver, so the harness your LLM writes is portable across engines. That portability is worth keeping in mind: generate one good harness, run it under both engines, and let their different mutation strategies find different bugs.
Structure-aware fuzzing (with code)
Here is the problem the toy target hid from us. Our parse_records crashes on the first malformed byte, so forwarding raw fuzzer bytes works fine. Real parsers are not so generous. They start with a cascade of format checks: a magic number, a version byte, a length that must be consistent with the total size, and maybe a checksum. Any input that fails an early check is rejected in the first few instructions. If you feed such a parser random bytes, 99%+ of your executions die at the front door and never reach the parsing logic where the interesting bugs live. Your million execs/sec are all bouncing off the same if (magic != EXPECTED) return -1;.
The fix is a structure-aware harness: instead of passing the fuzzer’s bytes through untouched, the harness carves them into the fields the target expects, so mutations land on the body of the format rather than repeatedly failing the header. The cleanest way to do this in libFuzzer is FuzzedDataProvider, a header-only helper, <fuzzer/FuzzedDataProvider.h>, that treats the fuzz input as a stream you can draw typed values from. Here is a harness of the kind you would prompt the LLM to write for a length-prefixed message format:
#include <fuzzer/FuzzedDataProvider.h>
#include <stdint.h>
#include <stddef.h>
#include <vector>
// Target under test: a message = [4-byte magic][1-byte version][2-byte length][body]
extern "C" int parse_message(const uint8_t *buf, size_t len);
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
FuzzedDataProvider fdp(data, size);
// Carve typed fields off the front of the fuzzer's bytes.
uint8_t version = fdp.ConsumeIntegral<uint8_t>();
// Let the fuzzer pick a body, but keep the message internally consistent.
std::vector<uint8_t> body = fdp.ConsumeRemainingBytes<uint8_t>();
uint16_t length = (uint16_t)body.size();
// Rebuild a *well-formed* message so we sail past the header checks
// and mutations exercise the body/parser instead of dying at the magic.
std::vector<uint8_t> msg;
msg.insert(msg.end(), {0x8B, 'M', 'S', 'G'}); // fixed magic
msg.push_back(version); // fuzzed version
msg.push_back((uint8_t)(length >> 8)); // length hi
msg.push_back((uint8_t)(length & 0xFF)); // length lo
msg.insert(msg.end(), body.begin(), body.end()); // fuzzed body
parse_message(msg.data(), msg.size());
return 0;
}The key move is that the harness spends the fuzzer’s entropy where it matters. The magic bytes are fixed constants, since there is no value in the fuzzer rediscovering them a billion times; the length field is computed from the body so the message is always internally consistent; and everything left over, the version byte and the whole body, is fuzzer-controlled. Now every single execution reaches the parser, and mutations explore version handling and body parsing instead of failing an integrity check.
If your toolchain lacks FuzzedDataProvider, which ships with LLVM but may be missing on your target compiler, the same carving is trivial to do by hand, and this is often clearer for beginners:
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
if (size < 3) return 0; // need at least version + length
uint8_t version = data[0];
uint16_t length = (uint16_t)((data[1] << 8) | data[2]);
const uint8_t *body = data + 3;
size_t body_len = size - 3;
// Clamp the attacker-supplied length to what we actually have, so the
// harness itself never over-reads — we want the *target* to be the one
// that mishandles length, not the harness.
if (length > body_len) length = (uint16_t)body_len;
uint8_t msg[8 + 65535];
size_t n = 0;
msg[n++] = 0x8B; msg[n++] = 'M'; msg[n++] = 'S'; msg[n++] = 'G';
msg[n++] = version;
msg[n++] = (uint8_t)(length >> 8);
msg[n++] = (uint8_t)(length & 0xFF);
for (size_t i = 0; i < length; i++) msg[n++] = body[i];
return parse_message(msg, n);
}One rule is easy to get wrong: the harness must be more careful with lengths than the target is. We clamp length to the bytes we actually hold so the harness never over-reads. Otherwise ASan would flag the harness, not the bug, and you would waste an afternoon triaging your own glue. The whole point is to hand a well-formed message to parse_message and let it be the code that mishandles the length internally. This is exactly the reasoning you should include in the LLM prompt: “carve the input into version/length/body, keep the framing valid, and make the harness itself memory-safe so any ASan report points at the target.” A model given that instruction produces a useful harness; a model told only “write a fuzzer” produces the raw-forwarding version that never gets past the magic.
Compile that structure-aware harness with -fsanitize=fuzzer,address and the abstract loop from the previous section becomes concrete. This is what a real libFuzzer session looks like:
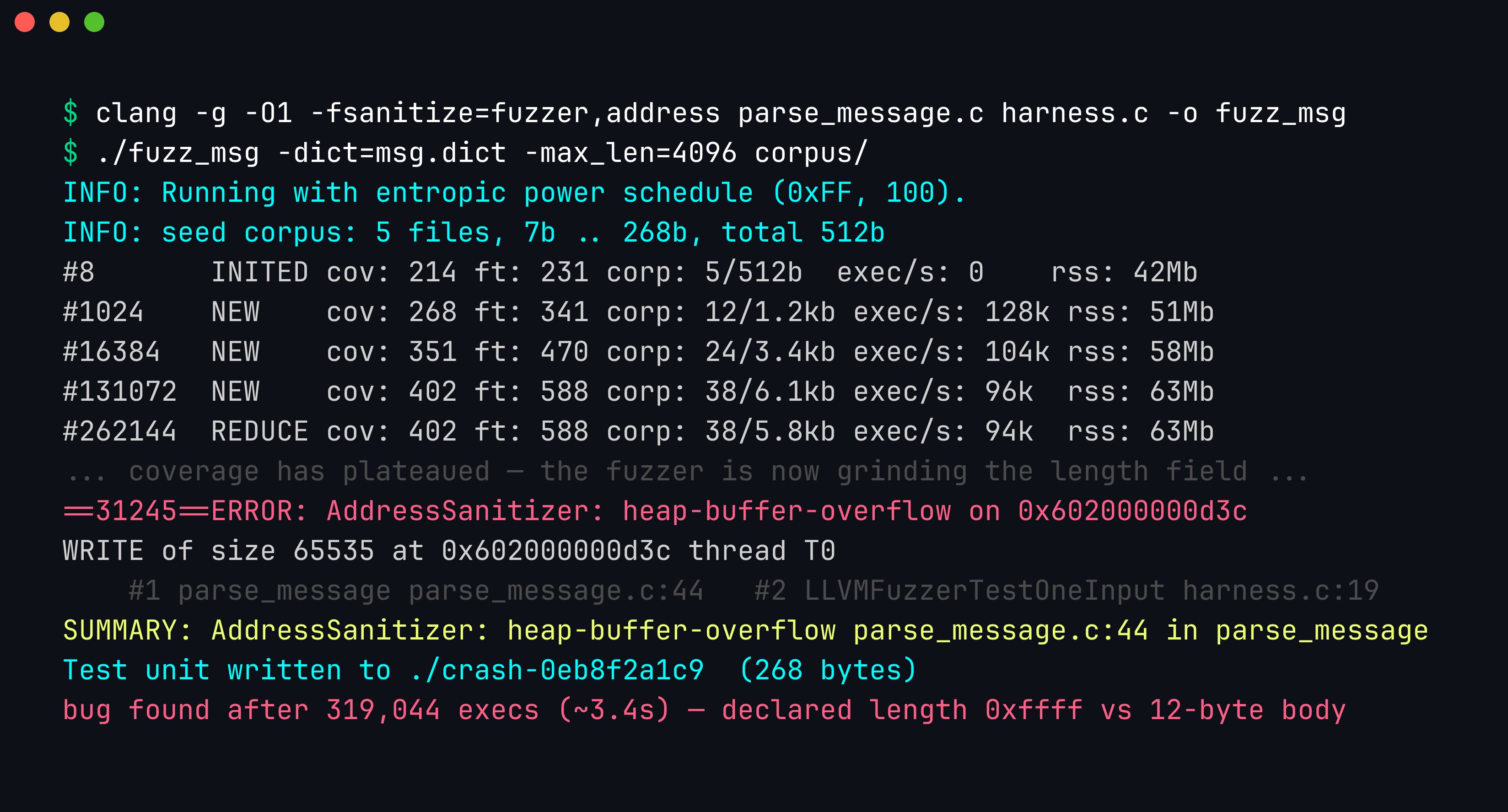
Reading a libFuzzer status line left to right: #131072 is the execution count, cov: 402 the number of edges hit, ft: 588 the feature count of edges plus hit-count buckets, corp: 38/6.1kb the evolving corpus, and exec/s: 96k the throughput that makes coverage-guided search viable. NEW marks a mutation that reached an unseen edge, and the corpus growing from 5 seeds to 38 is the fuzzer teaching itself the format. Once coverage plateaus the mutator grinds the length field until a declared 0xffff against a 12-byte body trips ASan, and libFuzzer writes the crashing bytes to a crash-* file for replay.
Two numbers to watch in that stream tell you whether the harness is any good. If cov climbs and then plateaus, the fuzzer has learned everything this harness can reach. Flat coverage early means the harness is stuck at a gate from bad framing, or the seeds are too weak. If exec/s is low, in the hundreds rather than the tens of thousands, the harness is doing too much per call, whether allocating, doing I/O, or leaking state, and every wasted millisecond is millions of inputs never tried.
Generating seeds and dictionaries with a local LLM (worked)
Structure-aware harnesses get you past framing checks. Seeds and dictionaries get you past value checks: the magic numbers, keywords, and enum tags scattered through the parser. Both are things a local model can produce in seconds, because generating “a few examples of a valid input” and “a list of the meaningful tokens in this format” is squarely in an LLM’s wheelhouse. Here is the worked flow against our [4-byte magic][1-byte version][2-byte length][body] message format.
(a) A minimal valid seed corpus. A fuzzer that starts from an empty or random corpus may spend a long time before it stumbles onto even one input that passes the header. Give it a handful of hand-shaped valid inputs, model-shaped in our case, and it starts from “almost valid” and mutates outward. We ask the local model for a small script that emits the seeds, which is more reliable than asking it to print raw bytes:
You are a fuzzing expert. The target parses messages of the form:
[4-byte magic 0x8B 'M' 'S' 'G'][1-byte version][2-byte big-endian length][body].
Write a short Python script that writes 5 minimal but VALID seed files
named seed_00..seed_04 into ./corpus/, covering: an empty body, a 1-byte
body, a typical body, version 0 and version 255. Output ONLY Python.A capable local coder model, in our case qwen3.6:35b-a3b via Ollama, returns something like:
import os
os.makedirs('./corpus', exist_ok=True)
def make_msg(version, body):
magic = b'\x8bMSG'
ver = bytes([version])
length = len(body).to_bytes(2, 'big')
return magic + ver + length + body
# Seed 0: empty body, version 0
with open('./corpus/seed_00', 'wb') as f:
f.write(make_msg(0, b''))
# Seed 1: 1-byte body, version 0
with open('./corpus/seed_01', 'wb') as f:
f.write(make_msg(0, b'A'))
# Seed 2: typical body, version 0
with open('./corpus/seed_02', 'wb') as f:
f.write(make_msg(0, b'Hello World!'))
# Seed 3: empty body, version 255
with open('./corpus/seed_03', 'wb') as f:
f.write(make_msg(255, b''))
# Seed 4: typical body, version 255
with open('./corpus/seed_04', 'wb') as f:
f.write(make_msg(255, b'Hello World!'))Each seed is a valid message, built by a clean make_msg helper that packs the magic, version, big-endian length, and body, so the fuzzer immediately has coverage of the “well-formed” path and can mutate the body, the version, and, most importantly, the length field to disagree with the actual body size, which is where length-handling bugs surface. The model covered the five cases we asked for, reaching the version-0 and version-255 edges by pairing them with empty and typical bodies rather than adding a distinct 1-byte case at each version. That is a reasonable reading of the spec that you would either accept or tighten in the prompt.
(b) A -dict= token dictionary. libFuzzer and AFL++ both accept a dictionary of interesting byte-strings; the mutator splices these tokens into inputs wholesale, so a 4-byte magic that would take 2^32 random tries to guess gets inserted verbatim. Ask the model to extract the format’s magic constants and keywords:
List the magic bytes, fixed tags, and keyword tokens for the message format
above as a libFuzzer dictionary. Use the name="\xHH..." syntax, one per line.
Output ONLY the dictionary.Output, saved as msg.dict and passed with -dict=msg.dict:
magic="\x8bMSG"
ver_zero="\x00"
ver_max="\xff"
len_zero="\x00\x00"
len_max="\xff\xff"The payoff is concrete. Suppose the parser has an inner gate like if (memcmp(body, "CONFIG", 6) == 0) parse_config(body);. Without the token "CONFIG" in the dictionary, the fuzzer must guess six exact bytes, 2^48 tries, before it ever reaches parse_config, which is effectively never. With config_tag="CONFIG" in the dictionary, the mutator drops that literal into the body on an early iteration, the branch flips, coverage records a new edge, and the input is saved for further mutation inside parse_config. Seeds and dictionaries are how you convert an unreachable code region into a reachable one, and a local LLM that has “read” the format, whether from a header, a spec, or the parser source you paste in, is an efficient way to produce both. The same generate-then-review discipline applies: eyeball the seeds and the dictionary, because a model can hallucinate a magic value, and a wrong constant simply wastes the slot.
Sanitizers beyond AddressSanitizer
We caught our overflow with AddressSanitizer, but ASan is only one member of a family. Each sanitizer instruments the program to make a different class of bug loud, and choosing the right one, or the right combination, is the difference between the fuzzer’s crashes being meaningful and the fuzzer silently running over bugs it cannot see. A sanitizer is the detection half of fuzzing; the fuzzer generates inputs, but without a sanitizer many bugs execute cleanly and you never learn they happened.
| Sanitizer | Flag | Catches | Typical cost |
|---|---|---|---|
| AddressSanitizer (ASan) | -fsanitize=address | Heap, stack, and global buffer overflows, use-after-free and double-free, out-of-bounds | ~2x slower, ~2–3x memory |
| UndefinedBehaviorSanitizer (UBSan) | -fsanitize=undefined | Signed integer overflow, invalid shifts, null deref, misaligned access, bad casts, unreachable | Low, often <20% |
| MemorySanitizer (MSan) | -fsanitize=memory | Reads of uninitialized memory | ~3x slower; needs all deps instrumented |
| ThreadSanitizer (TSan) | -fsanitize=thread | Data races, deadlocks in multithreaded code | ~5–15x slower, high memory |
| LeakSanitizer (LSan) | -fsanitize=leak, bundled in ASan | Memory leaks at exit | Negligible |
A few notes on when each earns its place:
- ASan is the default for a reason: memory corruption is the highest-severity, most-exploitable bug class, and ASan’s reports are the most actionable, giving you write-vs-read, size, allocation site, and the named overflown object. It combines spatial safety, whether you are inside the bounds of the object, with temporal safety, whether the object is still alive. LeakSanitizer rides along with ASan for free, catching allocations never released at exit.
- UBSan is cheap enough to run almost always, and it catches a whole category ASan is blind to:
intoverflow, shifting by more than the width of the type, dereferencing misaligned pointers. Many “impossible” logic bugs, and some real vulnerabilities like an integer overflow feeding a later allocation, are UBSan finds. Pair it with-fno-sanitize-recover=undefinedso undefined behaviour aborts like a crash rather than being logged and continuing, because a fuzzer needs the abort to register the input as a bug. - MSan answers a question ASan cannot: did we read memory before writing it? Uninitialized reads leak stack/heap contents and cause non-deterministic behaviour. The catch is that MSan needs every library in the process, including the C++ standard library, to be instrumented, or it reports false positives from uninstrumented code. That is why it is used less casually than ASan.
- TSan is the tool for concurrency. If your target spawns threads or you are fuzzing a lock-based data structure, TSan detects the data races that only manifest under specific interleavings and are otherwise nearly impossible to reproduce.
The important operational rule: ASan and MSan cannot be combined in one binary because they both rewrite memory access and conflict, and TSan is likewise its own build. So you build separate fuzz binaries per sanitizer and run them against the same corpus. ASan + UBSan + LSan do compose into a single binary, and that trio is the pragmatic default:
# Pragmatic default: memory + undefined behaviour + leaks, aborting on UB.
clang -g -O1 -fsanitize=fuzzer,address,undefined,leak \
-fno-sanitize-recover=undefined \
target.c -o fuzz_asan
# Separate binary for uninitialized-read detection.
clang -g -O1 -fsanitize=fuzzer,memory \
target.c -o fuzz_msanRun both across the shared corpus and you cover memory corruption, undefined behaviour, leaks, and uninitialized reads. This is another spot where the LLM is a natural fit: ask it to generate the per-sanitizer build commands and a small driver script that fans the corpus out across each binary, and you have your detection matrix set up in seconds.
The coverage feedback loop
The most advanced pattern in AI-assisted fuzzing, and the one Google’s OSS-Fuzz team has published real results on, is to close the loop between the fuzzer and the LLM. So far the model has been a one-shot draftsman: we asked for a harness, it produced one, we ran it. But the fuzzer emits a rich signal we can feed back to the model: the coverage report tells us exactly which functions and branches were never reached, and those uncovered regions are precisely where the harness is failing to do its job.
The workflow is iterative:
- Build with coverage. Compile the target with source-based coverage using
-fprofile-instr-generate -fcoverage-mappingalongside the fuzzer. - Fuzz for a while, then generate the coverage report:
# After a fuzzing run, produce a per-function coverage summary.
llvm-profdata merge -sparse default.profraw -o cov.profdata
llvm-cov report ./fuzz_target -instr-profile=cov.profdata
# Show the specific lines/branches that were NEVER executed.
llvm-cov show ./fuzz_target -instr-profile=cov.profdata \
--show-branches=count --region-coverage-lt=1 target.c- Feed the gaps back to the LLM. Extract the uncovered functions and the branch conditions guarding them, and hand them to the model with a targeted request:
The fuzzer has 78% line coverage of parser.c but these functions are
0% covered: decode_extension(), parse_tlv_nested(), handle_compressed().
They are only reached when byte[4] (the "flags" field) has bit 0x02 set
AND the body begins with the token "EXT". Here are their signatures and
the calling code: <paste>. Write (a) 3 new seed inputs that reach these
functions, and (b) an improved harness that sets the flags/token so
mutations exercise these branches. Output code only.- Add the new seeds/harness, re-fuzz, and repeat. Coverage climbs, and each round targets whatever is still dark.
Why this works: the LLM is good at the one reasoning step that is otherwise tedious for a human: reading a branch condition like if ((flags & 0x02) && starts_with(body, "EXT")) and working backwards to “what input satisfies this?” It is essentially doing lightweight, informal constraint-solving in natural language. It will not always be right, and for genuine path constraints you may still need a concolic engine or a symbolic executor to solve hard checks, but for the large class of “you just need the right magic byte / flag / keyword” gates, an LLM handed the source and the coverage gap produces a working seed far faster than manual analysis. OSS-Fuzz reported exactly this dynamic: LLM-generated and LLM-refined harnesses reached code that the previous human-written harnesses had left completely uncovered, on widely-fuzzed, mature projects, where the newly reached code was genuinely hard to get to.
Two guardrails keep the loop honest. First, verify the coverage actually moved after each iteration. A plausible-looking seed the model “promises” reaches a function may not, and coverage numbers are the ground truth. Second, watch for the model gaming the harness rather than the seeds: if it “reaches” a branch by hard-coding a call to the deep function directly, it has defeated the point: you now fuzz that function in isolation with an unrealistic calling context, potentially inventing bugs that cannot occur in practice. The loop should expand realistic reachability, not manufacture artificial entry points.
Continuous and differential fuzzing
Fuzzing is not a one-afternoon activity. Bugs surface as a function of CPU-hours, and the corpus is an asset that grows more valuable the longer it runs, which is why the mature model is continuous fuzzing in CI, exactly what Google’s OSS-Fuzz and its backend ClusterFuzz do for hundreds of open-source projects: every commit is fuzzed against the accumulated corpus on a fleet of machines, new crashes are automatically deduplicated, minimized, bisected to the offending commit, and filed, and fixes are verified when the crashing input stops crashing.
You can run a scaled-down version of the same loop in your own CI:
# .github/workflows/fuzz.yml — short per-commit fuzz + persistent corpus
name: continuous-fuzz
on: [push]
jobs:
fuzz:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Restore corpus
uses: actions/cache@v4
with:
path: corpus
key: fuzz-corpus-${{ github.ref }}
- name: Build
run: clang -g -O1 -fsanitize=fuzzer,address,undefined target.c -o fuzz_target
- name: Fuzz for 5 minutes on top of the saved corpus
run: ./fuzz_target -max_total_time=300 -print_final_stats=1 corpus
- name: Minimize corpus before saving it back
run: |
./fuzz_target -merge=1 corpus_min corpus
rm -rf corpus && mv corpus_min corpus
- name: Upload any crash reproducers
if: failure()
uses: actions/upload-artifact@v4
with: { name: crashes, path: crash-* }Two techniques in there deserve a beginner-level word:
Corpus minimization. Over weeks a corpus bloats to tens of thousands of inputs, many of which are redundant, covering the same edges as smaller, faster inputs. libFuzzer -merge=1, along with AFL++‘s afl-cmin, computes a minimal subset that preserves total coverage, throwing away the redundant inputs. A leaner corpus means every input is a more valuable stepping stone and each fuzzing cycle is faster. -minimize_crash=1 does the analogous thing to a single crashing input, shrinking a 200-byte reproducer down to the handful of bytes that actually trigger the bug, which makes triage dramatically easier.
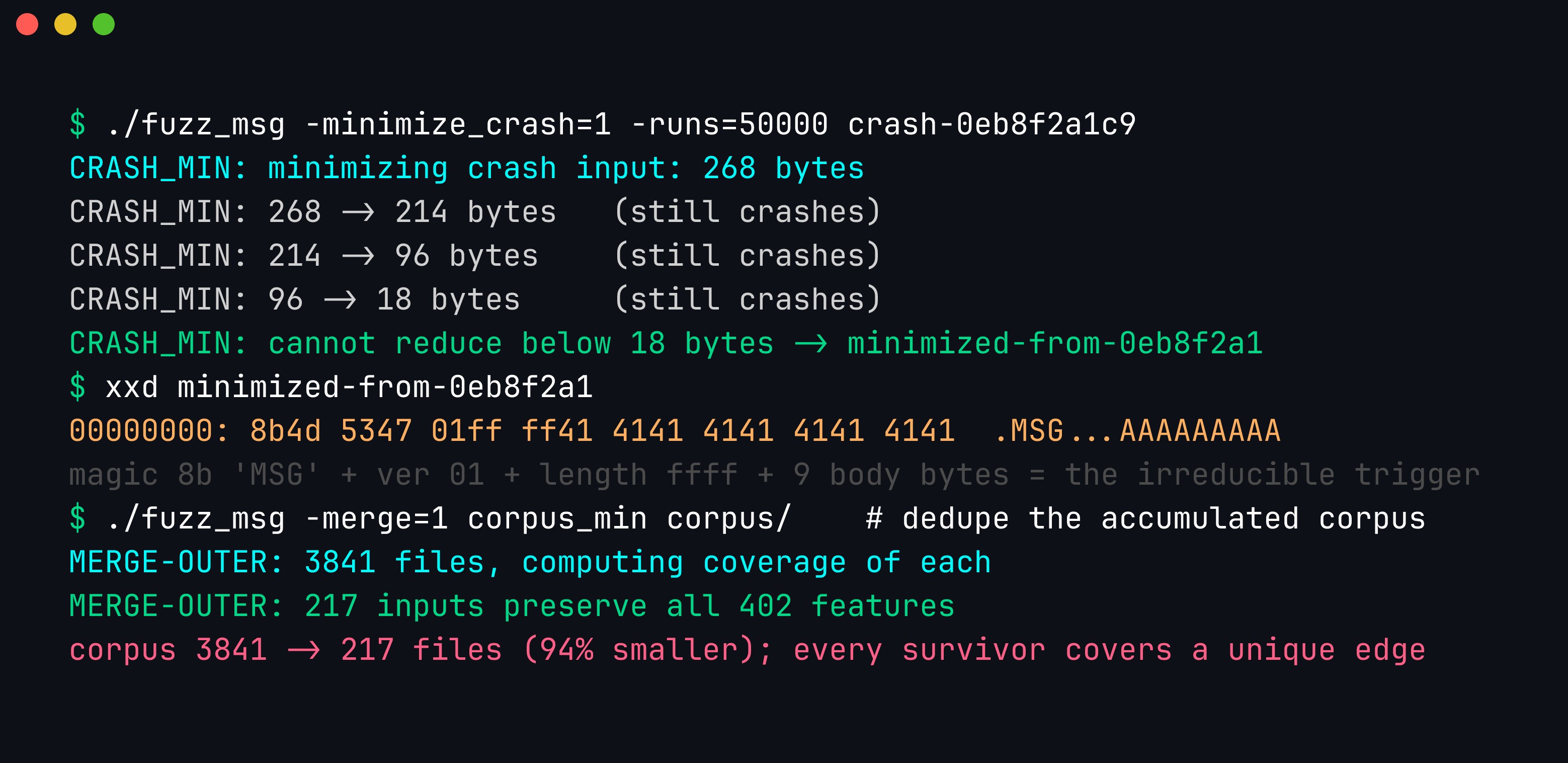
Both minimizers at work. -minimize_crash=1 repeatedly deletes and re-runs bytes, keeping only what still triggers the abort, so 268 bytes collapse to the 18-byte irreducible trigger of magic, version, and the 0xffff length that overruns the buffer, which is far easier to root-cause than the original blob. -merge=1 then computes the minimal subset of the accumulated corpus that preserves all 402 features, cutting 3,841 files to 217 so each survivor earns its place as a unique stepping stone.
Differential fuzzing. Some of the most valuable bugs never crash at all. They are divergences, where two implementations of the same specification disagree on the same input. Feed the identical bytes to two JSON parsers, two X.509 decoders, or an optimized and a reference implementation, and any difference in output is a bug in at least one of them, often a security-relevant parser-differential such as a request-smuggling-style desync, or a signature that one library accepts and another rejects. The harness compares the two and aborts on mismatch, so the fuzzer’s coverage feedback drives it toward inputs that make the implementations diverge:
extern int parse_A(const uint8_t*, size_t, char *out, size_t out_sz); // impl A
extern int parse_B(const uint8_t*, size_t, char *out, size_t out_sz); // impl B
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
char out_a[256] = {0}, out_b[256] = {0};
int ra = parse_A(data, size, out_a, sizeof out_a);
int rb = parse_B(data, size, out_b, sizeof out_b);
// The "oracle": both must accept/reject alike AND agree on output.
if ((ra == 0) != (rb == 0)) __builtin_trap(); // one accepted, one rejected
if (ra == 0 && memcmp(out_a, out_b, sizeof out_a) != 0)
__builtin_trap(); // both accepted, different result
return 0;
}The line that does the work is the oracle, the rule that decides “is this input a bug?” Writing a correct oracle is the hard, spec-reading part of differential fuzzing, and it is another place a local LLM helps: prompt it with the two APIs and the specification and ask it to enumerate the equivalences that must hold. For example, both must reject inputs with trailing garbage, canonical and non-canonical encodings must normalize to the same output, and a leading + must be rejected by both. Then encode those as assertions. The model drafts the oracle from the spec; you review it, because a wrong oracle produces a flood of false “divergences” that are really just the harness misunderstanding the format.
A harder worked example: an image/TLV parser
To see all of this land together, picture a more realistic target than our toy: a small image container parser, the kind that reads a signature, then walks a sequence of TLV (Type-Length-Value) chunks, each [2-byte type][4-byte length][length bytes of data], dispatching on type to sub-parsers for a header chunk, a palette chunk, a pixel-data chunk, and a comment chunk. This is representative of PNG, TIFF, and countless proprietary formats, and it is exactly the shape that has historically produced a long tail of memory-corruption CVEs.
Applying the full workflow:
- Structure-aware harness. Raw bytes almost never form a valid chunk stream, so you have the LLM write a harness that carves the fuzz input into a fixed signature, then a series of chunks whose 4-byte
lengthfields are computed from the data the fuzzer supplies, keeping the container well-framed so mutations reach the per-chunk sub-parsers instead of dying at the signature. You deliberately allow the fuzzer to make one chunk’s declaredlengthdisagree with its actual data, because that mismatch is the classic trigger. - Seeds and dictionary. Ask the model for a minimal valid image as the seed, containing a signature, one header chunk, and a tiny pixel chunk, plus a
-dict=of the four chunk-type tags and the signature bytes. Now the fuzzer can splice a validPLTE-style tag into a mutated chunk and immediately reach the palette sub-parser. - Sanitizer matrix. Build one binary with ASan+UBSan to catch spatial overflows in the pixel copy and integer overflow when
width * height * bytes_per_pixelis computed for an allocation, and a second with MSan to catch a palette chunk that declares 256 entries but supplies 4, leaving the decoder reading uninitialized palette memory into the output.
The bugs this surfaces are the bread and butter of parser fuzzing:
- Heap overflow in the pixel copy: a pixel-data chunk whose declared
lengthexceeds the buffer the header dimensions sized, so thememcpywrites past the allocation, which ASan flags as a heap-buffer-overflow WRITE. - Integer overflow in allocation sizing: a header with
width = 0x10000, height = 0x10000overflowswidth * height * 4to a small value; the parser allocates the small buffer but then writes the full image into it, where UBSan catches the multiply and ASan catches the resulting overflow. - Uninitialized read from a short palette: a palette chunk that under-supplies entries, so pixels index into never-initialized palette slots, which MSan flags as a use-of-uninitialized-value.
- Unbounded recursion / stack exhaustion: a chunk type that references another chunk, which the fuzzer nests deeply until the stack blows.
- Out-of-bounds read on a truncated chunk: a
lengthlarger than the remaining input, so a sub-parser reads past the end of the buffer, which ASan flags as a heap-buffer-overflow READ.
When one of these fires, the ASan report is again the map from crash to root cause. Here is the out-of-bounds read, the kind of thing the fuzzer surfaces within seconds of reaching the chunk dispatcher:
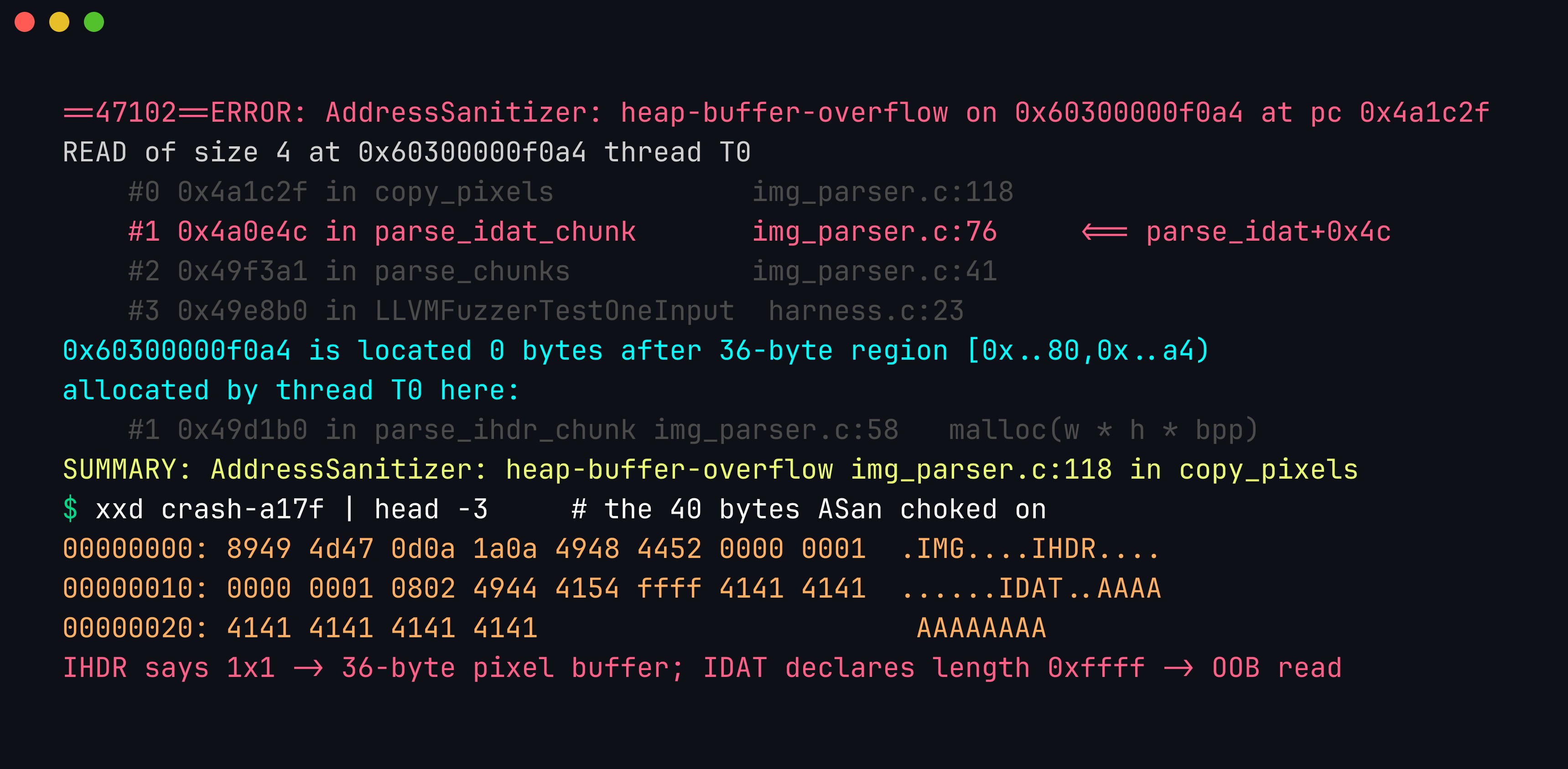
The trace pinpoints the defect without a debugger: the faulting frame is parse_idat_chunk+0x4c (img_parser.c:76) calling copy_pixels, the overrun object is a 36-byte region allocated by parse_ihdr_chunk from the 1x1 header dimensions, and the hexdump of the crashing input shows the mismatch that caused it: an IDAT chunk declaring a 0xffff length, 65,535, against a buffer sized for a single pixel. Symbolized frames from llvm-symbolizer, plus the allocation site, plus the input bytes, are everything you need to write the length-consistency check that fixes it.
Each of these is a real CVE pattern, and the point of the worked example is that the same repeatable pipeline finds them all: the local LLM drafts the structure-aware harness, seeds, and dictionary; you review them; the sanitizer matrix provides detection; coverage feedback, fed back to the LLM, chases the sub-parsers that are still dark; and CI runs it continuously so a regression that reintroduces one of these bugs is caught on the commit that adds it. The fuzzer and sanitizers are what actually found the bug, while the AI is what made it economical to stand up a competent harness, seed corpus, dictionary, and oracle for a non-trivial format in an afternoon instead of a week.
Where this fits, and its limits
To keep expectations calibrated: an LLM works alongside the fuzzer, the sanitizer, and the human reviewer. Its job is to remove harness-writing friction so you can fuzz more targets, faster. The failure modes are real: a hallucinated API call that will not compile, which is cheap to catch, or a subtly wrong harness that fuzzes the wrong thing and gives false confidence, which is expensive to catch. Always read the generated harness, and always confirm the fuzzer is reaching the code you intended by checking the coverage.
Used with that discipline, it is a real addition to a vulnerability-research workflow: point a local model at a library’s public headers, generate first-draft harnesses for every entry point, review and fix them, and let the fuzzer do what fuzzers do best.
Conclusion
It’s worth being honest about who did the work here. The fuzzer found the bug and the sanitizer made it obvious. The model just wrote the harness that let us start, which is the part most people put off doing. That turns out to matter more than it sounds, because the harness is usually the reason a target never gets fuzzed at all. And once you leave the toy example behind and start dealing with real formats, the seeds, dictionaries, and structure-aware harnesses the model can draft are what get the fuzzer past the header checks and into the code where the bugs actually live.
The one habit you can’t skip is reading what the model gives you. A bad harness either won’t compile, which you’ll notice immediately, or it’ll fuzz the wrong thing and leave you feeling productive while finding nothing. So generate, then review, every time. Do that and the payoff is mostly your own time back, spent on triage and root cause instead of boilerplate. Everything in this post runs end to end, and the lab works on stock macOS or Linux if you want to try it yourself. Keeping the model local is what makes the whole thing usable on code you can’t send anywhere, and it’s the workflow we teach, alongside AI-assisted vulnerability research and reverse engineering, in Advanced AI Security.
References
- LLVM — libFuzzer: a library for coverage-guided fuzz testing. https://llvm.org/docs/LibFuzzer.html
- Google — AddressSanitizer. https://clang.llvm.org/docs/AddressSanitizer.html
- Google Security Blog — AI-powered fuzzing: breaking the bug hunting barrier. OSS-Fuzz with LLM harnesses. https://security.googleblog.com/2023/08/ai-powered-fuzzing-breaking-bug-hunting.html
- AFL++ — American Fuzzy Lop plus plus. https://github.com/AFLplusplus/AFLplusplus
- Ollama — Run open-source LLMs locally. https://ollama.com/
- Qwen — Qwen3 open-weight code models. https://github.com/QwenLM/Qwen
- Google — OSS-Fuzz-Gen: LLM-powered fuzz-harness generation. https://github.com/google/oss-fuzz-gen
Get in Touch
Want to learn these techniques hands-on, or need help assessing your own mobile or AI stack? We run live and on-demand trainings, offer mobile-security certifications, and take on penetration-testing engagements. Pick the door that fits.
We respond within one business day. Visit our events page to see where we'll be next.


