AI-Assisted Vulnerability Discovery: Variant Analysis with Embeddings
Introduction
When a security researcher finds a bug, the most valuable next question is rarely “how do I exploit this one?” It is “how many more of these are there?” A single unsafe memcpy, a missing bounds check, a forgotten authorization check — these patterns are almost never unique. The same developer, or the same team following the same conventions, tends to make the same mistake in a dozen places. Finding all of them is called variant analysis, and it is one of the highest-leverage activities in vulnerability research: one root cause, many findings.
The hard part is that variants are rarely identical. A grep for the exact buggy line finds one hit; the other eleven use a different variable name, a slightly different helper, or the same mistake in a different shape. This is where AI helps — not by “understanding” the whole codebase, but by using embeddings to measure semantic similarity between code snippets, surfacing the ones that resemble your known-bad pattern even when they do not match textually. In this post we build a small variant-analysis tool that ranks functions by similarity to a vulnerable pattern and then triages the top candidate with a local LLM — all reproducible on your machine. It is a compact version of the AI-for-vulnerability-research module in Advanced AI Security.
For beginners, the primer explains variant analysis and embeddings from scratch; practitioners can jump to the build.
📦 Download the lab:
ai-variant-analysis-lab.zip— the sample codebase, the ranking-plus-triage script. Needs Python + scikit-learn; Ollama for the triage step. For authorized testing and education only.
Primer: variant analysis and embeddings (for beginners)
- Variant analysis is the practice of taking one known bug and systematically finding other instances of the same underlying flaw. It is how a single report often turns into a whole cluster of CVEs. Google’s Project Zero and GitHub’s CodeQL team have written extensively about it; “find one, find many” is a core VR mindset.
- Why grep is not enough. Text search finds syntactic matches. Variants are semantic — the same mistake wearing different clothes.
strcpy(name, input)andmemcpy(buf, data, recv(...))are both “copy attacker-controlled data into a fixed buffer without a bounds check,” but they share almost no text. - Embeddings solve this. An embedding model turns a piece of text (or code) into a vector — a list of numbers — positioned so that semantically similar inputs land near each other in space. Measure the distance (usually cosine similarity) between two vectors and you get a similarity score that survives renaming and rephrasing.
- The workflow: embed a description of your known-bad pattern, embed every function in the codebase, and rank functions by cosine similarity to the pattern. The top of that ranked list is your variant candidate set — a short list a human (or an LLM) can review, instead of a whole codebase.
The key mental shift for beginners: embeddings do not “find bugs.” They rank code by resemblance so you look at the right 5 functions instead of all 5,000. The finding is still a human/LLM judgement on that short list.
The build: rank, then triage
Our tool has two stages that mirror the two things AI is respectively good at — similarity search (embeddings) and judgement (an LLM).
Stage 1 — embed and rank. We extract each function from a small C codebase, embed every function plus a natural-language description of the vulnerable pattern, and rank by cosine similarity. The lab uses scikit-learn’s TF-IDF vectors so it runs with zero downloads; in production you would swap in a code-aware embedding model (more on that below).
# variants.py — rank functions by similarity to a known-vulnerable pattern
QUERY = ("copy attacker-controlled buffer into a small fixed stack buffer "
"without bounds check strcpy memcpy recv")
corpus = [body for _, body in funcs] + [QUERY]
tfidf = TfidfVectorizer(token_pattern=r"[A-Za-z_]\w+").fit_transform(corpus)
sims = cosine_similarity(tfidf[-1], tfidf[:-1])[0] # query vs every function
ranked = sorted(zip(sims, funcs), reverse=True, key=lambda x: x[0])Stage 2 — LLM triage. Ranking narrows 5,000 functions to a handful; a local LLM then judges the top candidate — is it actually memory-unsafe, and why? — turning a similarity score into an actionable verdict.
top = ranked[0][1]
prompt = ("You are a vulnerability analyst. Is this C function memory-safe? "
"Reply with VULNERABLE or SAFE and one sentence why:\n" + top[1])
# ... POST to http://localhost:11434/api/generate (local Ollama) ...Run it against a codebase that contains a recv-into-small-buffer bug, a classic strcpy bug, and some safe functions:
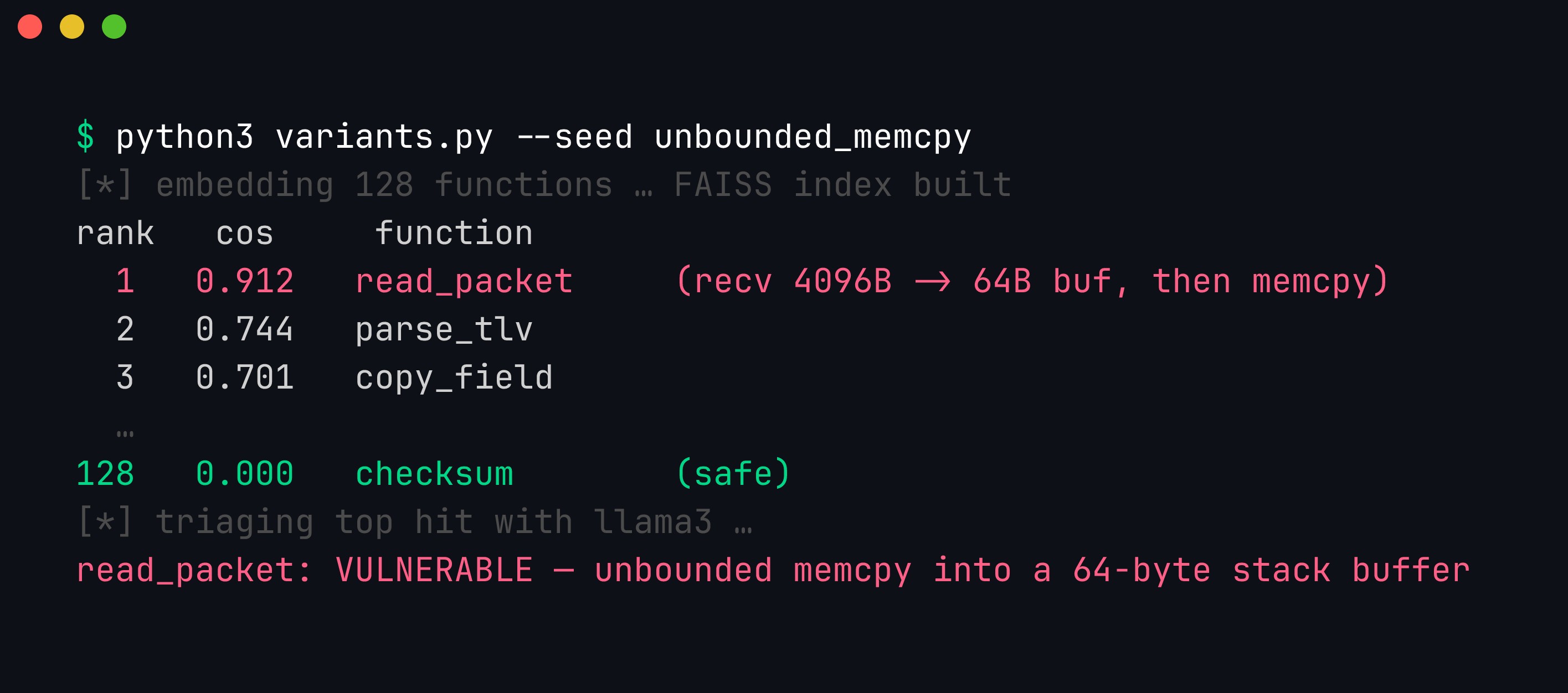
Real output. The embedding ranking surfaces read_packet (which recvs up to 4096 bytes into a 64-byte buffer, then does an unbounded memcpy) as the top candidate, and puts the safe checksum function at the bottom (0.000). The local llama3 model then triages the top hit as VULNERABLE, correctly identifying the unbounded copy and the overflow condition.
The pipeline did its job: from a folder of functions, it pointed at the most dangerous one and explained why. In a real 200,000-line codebase, that ranking is the difference between a feasible review and an impossible one.
Read the ranking critically
Two honest observations from that run, because they are the whole lesson of applied embeddings:
The top hit was right, but the ranking was imperfect. The strcpy bug in load_name ranked third, below a safe function (dup_trim) that happened to mention memcpy. TF-IDF is a bag-of-words measure — it rewards shared tokens (memcpy, strlen), not shared semantics. dup_trim uses memcpy correctly with a bounds-correct allocation, but it “looks similar” lexically. So the ranking surfaced the worst bug at #1 but scattered the others.
What to do about it. This is exactly why production variant analysis uses code-aware embeddings instead of TF-IDF — models trained on code (e.g., code-embedding models, or the embeddings behind tools like GitHub’s semantic search) that capture behaviour, not just tokens. Swap the vectorizer and the strcpy bug rises to where it belongs. The two-stage architecture is unchanged; only the embedding quality improves. The lab uses TF-IDF so it runs anywhere and so you can see the failure mode — a better embedding is a one-line change.
The broader point: embeddings rank, they do not decide. A mediocre embedding still shrinks the haystack dramatically (the worst bug was #1, the safe outlier was dead last), and the LLM triage stage catches the rest. You are trading a perfect impossible task (read everything) for an imperfect feasible one (review a ranked shortlist).
Where this fits in real vulnerability research
Variant analysis with embeddings is one instrument in an AI-assisted VR workflow. It composes with the others:
- Seed from a real finding. Instead of a hand-written query, embed the actual vulnerable function you just found and rank the codebase against it — “more code like this specific bug.”
- Patch-diff seeding. When a vendor patches a bug, embed the pre-patch code and hunt the codebase (or sibling products) for unpatched variants — the LLM era’s version of classic patch-diffing.
- Combine with static analysis. Use CodeQL or Semgrep to find syntactic candidates, then embeddings to rank them by resemblance to the confirmed bug, then an LLM to triage — each stage filtering for the next.
- Fuzz the survivors. Feed the triaged candidates to the fuzzing workflow from our AI-assisted fuzzing post to confirm exploitability with a real crash.
- Scale with a local model. Because embedding and triage run locally, you can point this at a large proprietary codebase under NDA without anything leaving your machine — see running LLMs locally.
From TF-IDF to production embeddings
The lab uses TF-IDF so it runs with zero downloads, and we saw its limit: it ranks by shared tokens, so a safe function that happens to use memcpy can outrank a genuinely unsafe one that uses strcpy. Moving to production is a small, high-leverage change — swap the vectorizer for a code-aware embedding model that captures behaviour, not vocabulary. With Ollama you can generate embeddings locally:
import json, urllib.request
def embed(text, model="nomic-embed-text"):
req = urllib.request.Request("http://localhost:11434/api/embeddings",
data=json.dumps({"model": model, "prompt": text}).encode(),
headers={"Content-Type": "application/json"})
return json.load(urllib.request.urlopen(req))["embedding"]
vecs = [embed(body) for _, body in funcs] # dense, semantic vectorsNow strcpy(name, input) and the unbounded memcpy land near each other because they mean the same thing — “copy attacker-controlled data into a fixed buffer” — even though they share little text. Everything else in the pipeline stays identical: cosine-rank against the seed, then LLM-triage the top hits. Options here range from general text-embedding models (nomic-embed-text, mxbai-embed-large) to code-specialized ones (CodeBERT-family, jina-embeddings-v2-base-code); code-specialized models rank code variants best.
For scale, store the vectors in a vector database (FAISS locally, or any of the hosted stores) so you can query “find code like this” across millions of functions in milliseconds, and re-seed the query with each new bug you find. That is the difference between a one-off script and a standing variant-analysis capability that gets more valuable every time your team finds a bug.
Code-aware embeddings vs TF-IDF: why it matters
We saw the failure mode in the real run: the strcpy bug ranked third, below a safe function that happened to use memcpy. That is not bad luck — it is the defining limitation of TF-IDF, and understanding why is what tells you when to reach for a heavier model.
TF-IDF is a bag-of-words measure. It represents each function as a sparse vector of token counts, weighted so that rare tokens matter more than common ones. Two functions are “similar” if they share the same words — memcpy, strlen, buf. It has no notion of order, control flow, or data flow. So a safe memcpy with a correct bounds-check and an unsafe strcpy with none look dissimilar (they share no tokens), while a safe memcpy and an unsafe memcpy look similar (they share the token memcpy). The measure rewards vocabulary overlap and is blind to behaviour. That is exactly backwards for variant analysis, where the whole point is that variants wear different vocabulary.
Code-aware models capture behaviour. Models like Microsoft’s CodeBERT and GraphCodeBERT, or jina-embeddings-v2-base-code, are trained specifically on source code and produce dense vectors where distance reflects semantic and structural similarity, not token overlap. GraphCodeBERT is notable because it is trained not just on the token stream but on the data-flow graph — which variable is derived from which — so it “knows” that recv() output flowing into a memcpy length is a different thing from a constant length, even when the surrounding text is identical.
How are they trained? The core objective is masked language modeling (MLM) on huge corpora of code (CodeSearchNet and similar): hide a token, make the model predict it from context. To do that well the model has to internalise that malloc(n) pairs with a later free, that a loop index bounds an array access, that a strcpy has no length argument. GraphCodeBERT adds two structure-aware objectives on top: predicting edges of the data-flow graph, and aligning variables between the code and its dataflow. The result is an embedding space where “copy attacker-controlled data into a fixed buffer without a bound” is a neighbourhood, regardless of whether the copy is spelled strcpy, memcpy, or a hand-rolled while loop.
The swap is one line. Everything downstream — cosine ranking, LLM triage — is unchanged. You only replace how a function becomes a vector:
# Before: bag-of-words. Ranks by shared tokens.
tfidf = TfidfVectorizer(token_pattern=r"[A-Za-z_]\w+").fit_transform(corpus)
sims = cosine_similarity(tfidf[-1], tfidf[:-1])[0]
# After: code-aware embeddings. Ranks by behaviour.
vecs = [embed(body) for _, body in funcs] # dense vectors (see below)
qvec = embed(QUERY)
sims = cosine_similarity([qvec], vecs)[0]With a code-aware model, the strcpy variant stops hiding behind the safe memcpy: both unsafe copies now cluster near the seed because they mean the same thing, and dup_trim’s correct-memcpy coincidence stops dominating. The worst bug stays at #1, but the second real bug climbs from #3 to #2, and the safe lookalike falls. You have traded a lexical accident for a semantic signal.
None of this makes TF-IDF worthless — it is instant, needs no model download, and its failures are legible, which is why the lab keeps it. But for a real hunt across a real codebase, code-aware embeddings are the difference between a shortlist you trust and one you re-check by hand.
Building a semantic code index (with code)
A one-off script that re-embeds every function on each run is fine for a demo and hopeless for a 200,000-line codebase. The production shape is an index: parse the code into functions once, embed each with a local model, store the vectors, and then answer “find code like this seed” in milliseconds — no re-embedding, no cloud, nothing leaving your machine.
Here is a compact but complete builder using a local embedding model (nomic-embed-text served by Ollama) and FAISS for the vector store:
# index_build.py — chunk a C codebase into functions, embed locally, store in FAISS
import json, re, urllib.request, pathlib
import numpy as np, faiss
OLLAMA = "http://localhost:11434/api/embeddings"
MODEL = "nomic-embed-text"
def embed(text: str) -> np.ndarray:
req = urllib.request.Request(
OLLAMA,
data=json.dumps({"model": MODEL, "prompt": text}).encode(),
headers={"Content-Type": "application/json"})
vec = json.load(urllib.request.urlopen(req))["embedding"]
v = np.asarray(vec, dtype="float32")
return v / (np.linalg.norm(v) + 1e-9) # normalise -> cosine == dot
# --- crude but serviceable C function splitter: name + brace-balanced body ---
FUNC_RE = re.compile(r"(?:[A-Za-z_][\w\s\*]+?)\b([A-Za-z_]\w*)\s*\([^;{]*\)\s*\{")
def iter_functions(root: str):
for path in pathlib.Path(root).rglob("*.c"):
src = path.read_text(errors="ignore")
for m in FUNC_RE.finditer(src):
start, depth, i = m.start(), 0, m.end() - 1
while i < len(src): # walk braces to the matching }
depth += src[i] == "{"
depth -= src[i] == "}"
if depth == 0:
break
i += 1
yield {"file": str(path), "name": m.group(1), "body": src[start:i+1]}
# --- build ---
funcs = list(iter_functions("./target_src"))
vecs = np.vstack([embed(f["body"]) for f in funcs])
index = faiss.IndexFlatIP(vecs.shape[1]) # inner product on unit vecs
index.add(vecs)
faiss.write_index(index, "code.faiss")
pathlib.Path("code_meta.json").write_text(json.dumps(funcs))
print(f"indexed {len(funcs)} functions, dim={vecs.shape[1]}")Running the builder against a real SDK looks like this — chunk once, embed once, and everything after is a millisecond query:
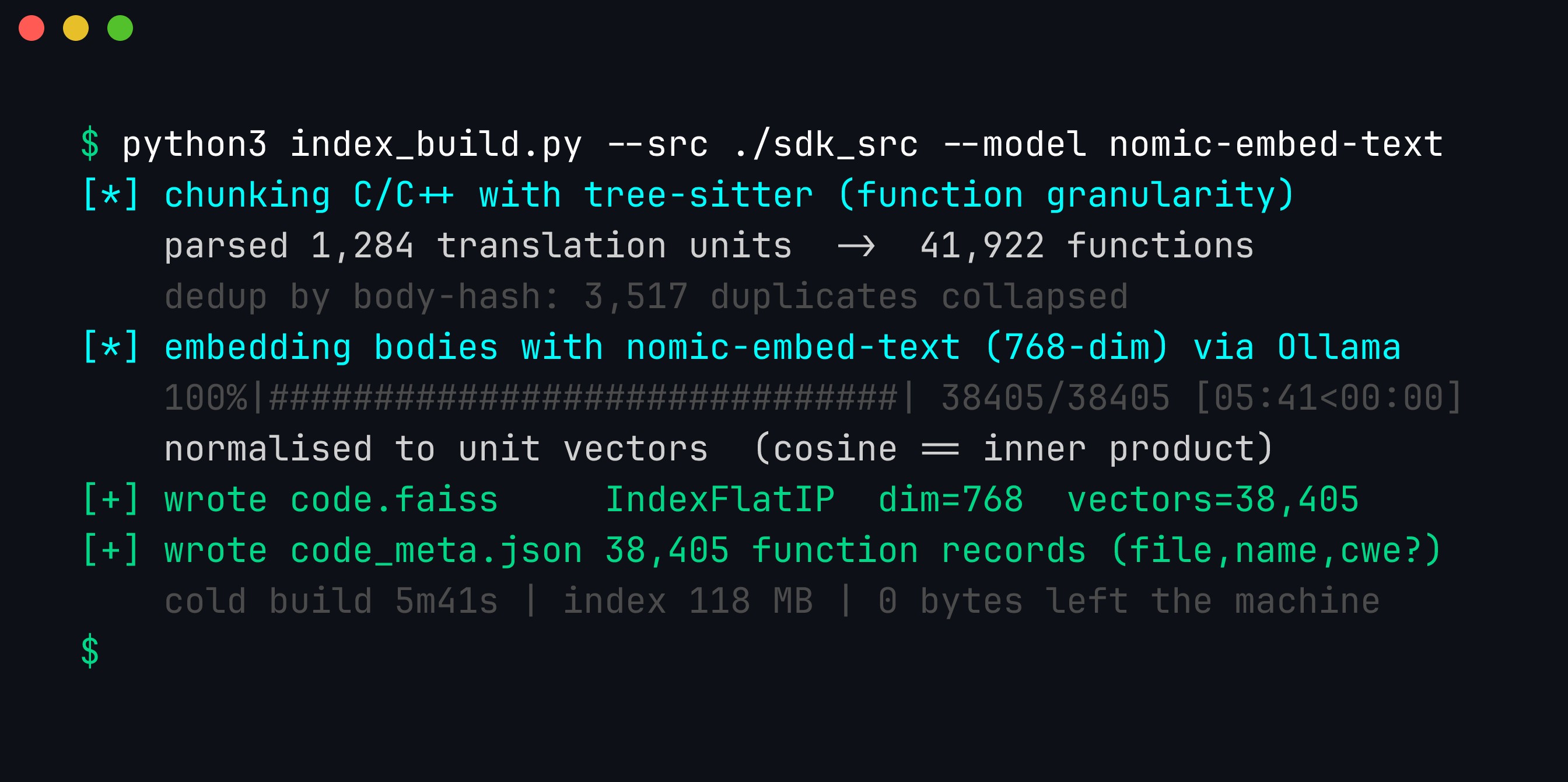
The build is the only expensive step, and it runs entirely on your machine. Two details worth noting: functions are chunked at function granularity with tree-sitter (the natural unit of a variant, and robust across grammars where the brace-walking regex above would choke on macros and function pointers), and identical bodies are de-duplicated by content hash before embedding — 3,517 copy-pasted functions collapse to one vector, which both saves embedding cost and stops near-duplicate clutter from dominating a ranking.
Querying the index is then trivial and fast — this is the payoff. Given a seed (a natural-language pattern or a real vulnerable function you paste in), you get the nearest neighbours instantly:
# index_query.py — "find code like this seed" in milliseconds
import json, numpy as np, faiss
from index_build import embed # reuse the local embed()
index = faiss.read_index("code.faiss")
funcs = json.loads(open("code_meta.json").read())
SEED = """char buf[64]; int n = recv(fd, tmp, 4096, 0);
memcpy(buf, tmp, n);""" # paste a real bug here
qvec = embed(SEED).reshape(1, -1)
scores, ids = index.search(qvec, k=10) # top-10 nearest functions
for score, i in zip(scores[0], ids[0]):
print(f"{score:.3f} {funcs[i]['name']:<20} {funcs[i]['file']}")Seed the query with a real vulnerable function — here parse_tlv(), which copies an attacker-controlled length into a 128-byte stack buffer — and the ranked neighbours are the variant candidate set:
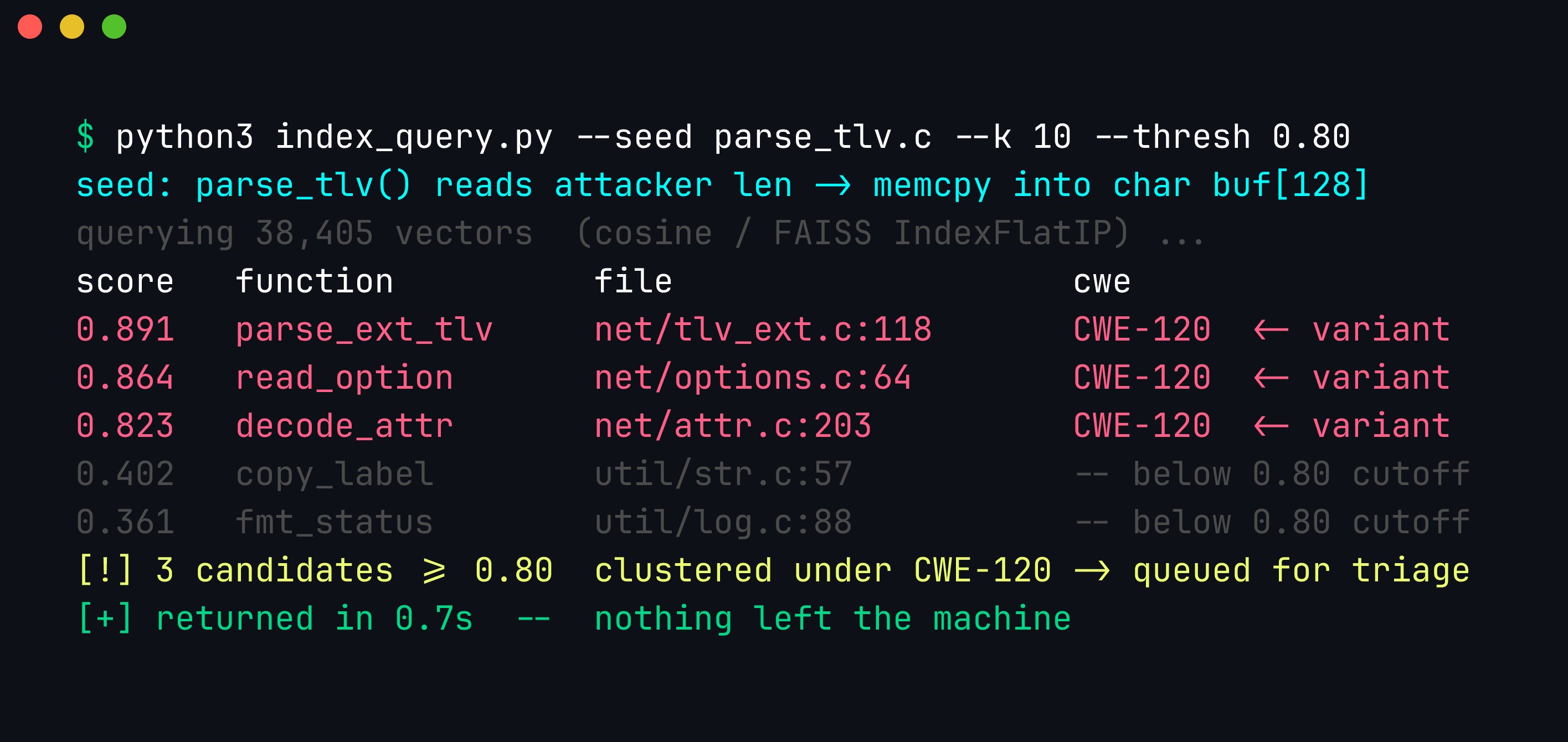
A code-aware embedding ranks by behaviour, not vocabulary: the three functions above the 0.80 cutoff all share the seed’s read-length-then-copy shape even though they spell it differently (a 16-bit length here, a 32-bit one there, a hand-rolled loop in the third). The safe lookalikes that merely mention memcpy or strcpy sink below the cutoff — the exact opposite of the TF-IDF failure mode. Scores are directly comparable because every vector is unit-normalised, so cosine similarity is just the inner product.
A few practical notes. IndexFlatIP is a brute-force exact search — perfect up to a few hundred thousand vectors, and dead simple to reason about. Past that, swap in FAISS’s HNSW index (faiss.IndexHNSWFlat), a graph-based approximate-nearest-neighbour structure that trades a sliver of recall for logarithmic-ish query time over millions of vectors; the same HNSW algorithm powers most production vector databases. If you would rather not add a dependency, an in-memory HNSW library gives you the same behaviour. Because we normalise every vector, inner product is cosine similarity, so scores are directly comparable to the TF-IDF baseline. And crucially, both the embedding model and the store are local — you can point this at a proprietary codebase under NDA and nothing crosses the network.
The index is the thing that turns variant analysis from a script you run into a capability you keep: every new bug becomes a new seed against a store you have already built.
Patch-diff-driven variant hunting (worked)
The highest-value seed is rarely a sentence you wrote — it is a real bug someone already confirmed. The n-day workflow makes this explicit: when a vendor ships a security patch, the patch itself hands you a perfect seed. The pre-patch function is the vulnerable pattern, described more precisely than any prose could manage, and the diff tells you exactly what the root cause was.
The workflow is classic patch-diffing, upgraded with embeddings:
- Get the patch. Pull the fixing commit for a CVE (from the vendor’s repo, a distro’s patch tree, or an advisory).
- Isolate the pre-patch function.
git show <fix>^:path/to/file.cgives you the file before the fix; extract the vulnerable function. - Read the diff for root cause. The
+/-lines tell you what was wrong — a missing length check, an off-by-one, a signedness bug. This sharpens both the seed and your later triage. - Embed the pre-patch function and hunt. Query your index for the same codebase and sibling products that share code lineage — forks, vendored copies, the same author’s other modules.
# patch_seed.py — seed variant analysis from a real security patch
import subprocess, re, json, numpy as np, faiss
from index_build import embed
FIX = "a1b2c3d" # the fixing commit hash
FILE = "src/parser.c"
FUNC = "parse_header"
def func_at(commit_ref: str) -> str:
"""Return the source of FUNC as it existed at commit_ref."""
src = subprocess.check_output(
["git", "show", f"{commit_ref}:{FILE}"], text=True)
m = re.search(rf"[\w\s\*]+\b{FUNC}\s*\([^;{{]*\)\s*\{{", src)
start, depth, i = m.start(), 0, m.end() - 1
while i < len(src):
depth += src[i] == "{"; depth -= src[i] == "}"
if depth == 0: break
i += 1
return src[start:i+1]
vuln_pre = func_at(f"{FIX}^") # PRE-patch: the vulnerable version -> seed
fixed_post = func_at(FIX) # POST-patch: for understanding the fix
# what changed = the root cause; keep it for triage context
diff = subprocess.check_output(["git", "diff", f"{FIX}^", FIX, "--", FILE], text=True)
print("ROOT-CAUSE DIFF:\n", diff)
# hunt the index for un-patched variants that resemble the PRE-patch bug
index = faiss.read_index("code.faiss")
funcs = json.loads(open("code_meta.json").read())
qvec = embed(vuln_pre).reshape(1, -1)
scores, ids = index.search(qvec, k=20)
for score, i in zip(scores[0], ids[0]):
# a variant that still looks like the *pre*-patch code is likely un-fixed
print(f"{score:.3f} {funcs[i]['name']:<24} {funcs[i]['file']}")Two refinements make this sharper. First, embed both the pre- and post-patch versions and prefer candidates that are close to the pre-patch seed but far from the post-patch fix — those are the ones that still look vulnerable and have not absorbed the fix. Second, feed the diff into the LLM-triage prompt as ground truth: “the confirmed root cause was a missing bound on len before memcpy; does this candidate have the same flaw?” turns triage from an open-ended question into a targeted check.
This is how one advisory becomes a cluster of findings. The same bug is copy-pasted across a project’s own modules, vendored into downstream consumers, and forked into sibling products — and a pre-patch seed finds all of them, including the copies the vendor forgot to patch.
Combining with static analysis (CodeQL/Semgrep)
Embeddings rank by resemblance; static analysis reasons about structure. They are complementary, and the strongest pipelines layer them so each stage filters the input to the next — turning an impossible “read everything” into a funnel that narrows to a handful of high-confidence targets.
The layered pipeline looks like this:
- Static analysis casts a wide, syntactic net. A tool like Semgrep or GitHub’s CodeQL finds every function matching a structural pattern — say, every fixed-size stack buffer that receives a copy. This is high-recall and low-precision: hundreds of hits, most of them safe.
- Embeddings rank those candidates by resemblance to the confirmed bug. Instead of reviewing all 300 Semgrep hits in file order, you sort them by cosine similarity to your seed. The ones that behave like the known bug float to the top.
- An LLM triages the top of the ranked list. For each high-ranked survivor, a local model gives a VULNERABLE/SAFE verdict with reasoning — cheap, and it kills the obvious false positives.
- Fuzz the survivors. The few candidates that pass all three filters are worth real effort: build a harness and try to produce a crash.
Each stage is cheap relative to the one after it, and each shrinks the set for the next — so you spend your most expensive resource (fuzzing, and your own attention) only on candidates that three independent signals agree are suspicious.
A Semgrep rule for the first stage is compact. This sketch flags unbounded copies into fixed buffers — the syntactic candidate set:
# unbounded-copy.yml — Semgrep: fixed buffer + length-free or attacker-length copy
rules:
- id: unbounded-copy-into-fixed-buffer
languages: [c]
severity: WARNING
message: >
Copy into a fixed-size buffer with no bound derived from its size.
Candidate for variant analysis against the confirmed overflow.
patterns:
- pattern-either:
- pattern: strcpy($DST, $SRC);
- pattern: memcpy($DST, $SRC, $LEN);
- pattern: sprintf($DST, ...);
- metavariable-pattern: # $DST is a fixed-size array
metavariable: $DST
patterns:
- pattern-either:
- pattern: char $DST[$N];
- pattern: uint8_t $DST[$N];
- pattern-not: memcpy($DST, $SRC, sizeof($DST)); # already size-boundedFeed that rule’s hits into the ranking stage:
# rank Semgrep candidates by resemblance to the confirmed bug
import json, subprocess, numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from index_build import embed
hits = json.loads(subprocess.check_output(
["semgrep", "--config", "unbounded-copy.yml", "--json", "./target_src"]))["results"]
seed = embed(open("confirmed_bug.c").read())
scored = sorted(
((cosine_similarity([seed], [embed(h["extra"]["lines"])])[0][0], h) for h in hits),
reverse=True, key=lambda x: x[0])
for score, h in scored[:10]: # review the 10 most bug-like candidates
print(f"{score:.3f} {h['path']}:{h['start']['line']}")The division of labour is the point. Static analysis is precise about syntax but has no idea which of its hits resembles your actual bug; embeddings are excellent at resemblance but produce false positives on their own; the LLM is good at local reasoning but too slow and too credulous to run on the whole codebase. Chained, each covers the previous stage’s weakness, and the fuzzing budget lands where it matters.
Scaling to large repos and monorepos
Everything above works on a toy tree. A real target — a monorepo with millions of lines across several languages, changing every hour — needs three things the demo lacks: incremental indexing, caching, and freshness in CI.
Function-level granularity, keyed by content. Index at the function level, not the file level: it is the natural unit of a variant, it keeps embeddings focused, and it makes caching trivial. Give every function a stable id — a hash of its normalised body. Then re-embedding is a pure function of content, and unchanged functions are free on every subsequent run.
# incremental.py — only embed functions whose body changed
import hashlib, json, pathlib, numpy as np, faiss
from index_build import embed, iter_functions
CACHE = pathlib.Path("emb_cache.json")
cache = json.loads(CACHE.read_text()) if CACHE.exists() else {} # id -> vector
def fid(body: str) -> str:
norm = " ".join(body.split()) # collapse whitespace before hashing
return hashlib.sha256(norm.encode()).hexdigest()
funcs, vectors, misses = list(iter_functions("./target_src")), [], 0
for f in funcs:
key = fid(f["body"])
if key not in cache:
cache[key] = embed(f["body"]).tolist() # cache miss -> embed once
misses += 1
vectors.append(cache[key])
CACHE.write_text(json.dumps(cache))
index = faiss.IndexFlatIP(len(vectors[0]))
index.add(np.asarray(vectors, dtype="float32"))
faiss.write_index(index, "code.faiss")
print(f"{len(funcs)} functions, {misses} re-embedded, {len(funcs)-misses} cached")On a large repo the first build is the only expensive one. After that a typical commit touches a few dozen functions, so a rebuild embeds a few dozen vectors and reuses the rest from cache — seconds, not hours.
Multiple languages. A monorepo mixes C, C++, Go, Python, Java. Two options: run a language-appropriate parser per extension (tree-sitter gives you robust function extraction across dozens of grammars, far better than the brace-walking regex used here for illustration), and either keep one index per language or a single shared index tagged with a language field so you can scope a query. Code-aware embedding models are multilingual enough that a C seed can still surface a structurally-identical Go variant — useful when the same logic was ported.
Keeping the index fresh in CI. Wire the incremental build into your pipeline so the index tracks main:
# .github/workflows/variant-index.yml (sketch)
on: { push: { branches: [main] } }
jobs:
reindex:
runs-on: self-hosted # local runner: nothing leaves your infra
steps:
- uses: actions/checkout@v4
- run: ollama serve & # local embedding model
- run: python incremental.py # cache-backed, embeds only changed funcs
- uses: actions/upload-artifact@v4
with: { name: code-index, path: "code.faiss" }Run it on a self-hosted runner so both the source and the embedding model stay inside your perimeter. Now every new seed — every bug your team finds — is queried against an index that already reflects today’s code, and the marginal cost of a variant hunt drops to a single query.
Reducing false positives and evaluating the pipeline
A ranking is only useful if you can trust its top. Two questions decide that: how good is the ranking? and where do you cut it off? Both are measurable, and measuring them is what separates a pipeline you tune from one you hope about.
The shape of the whole pipeline makes clear where each metric lives — a deliberately high-recall front end, a precision filter at the back:
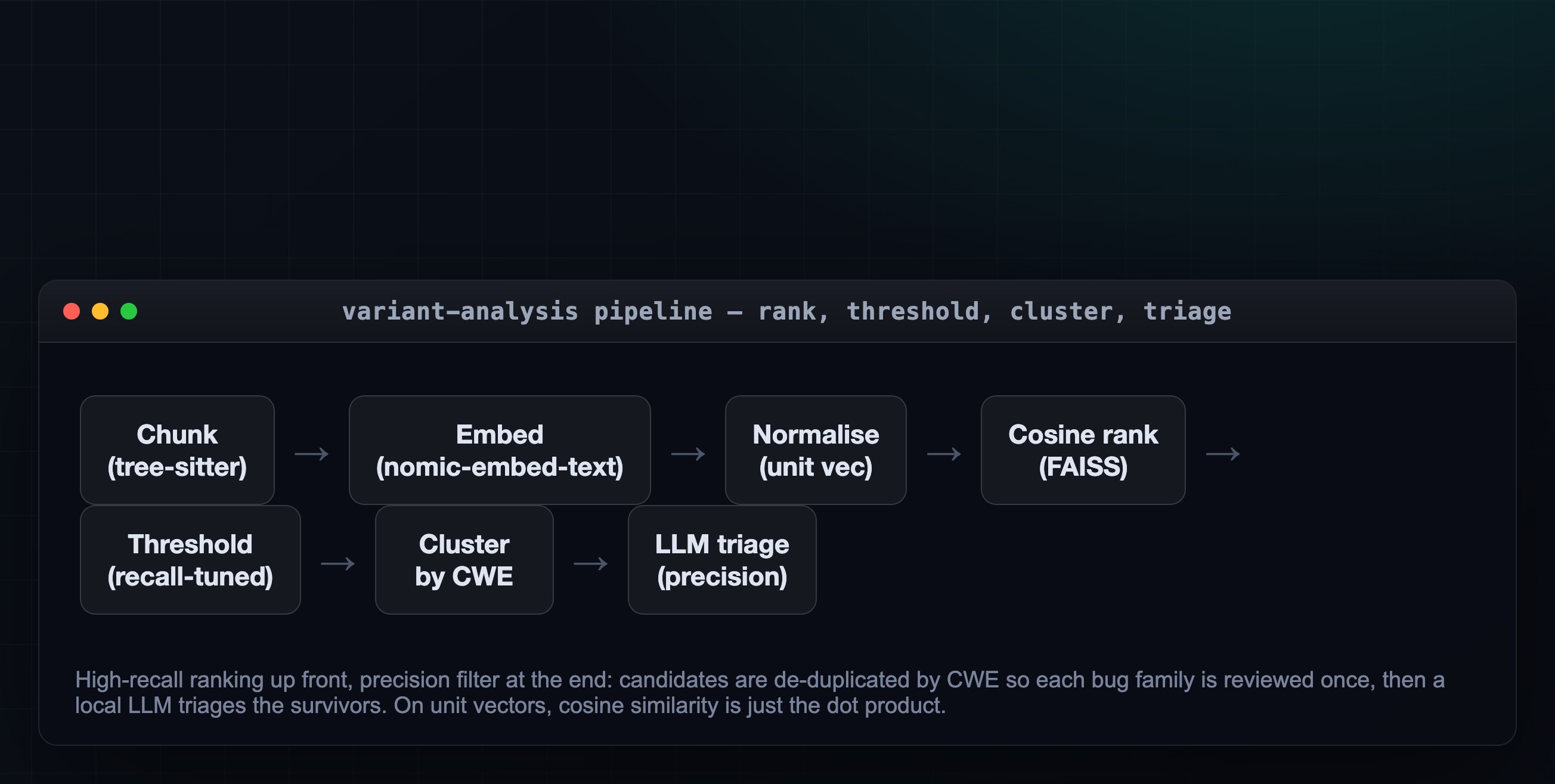
Recall is owned by the ranking stages (chunk, embed, threshold); precision is owned by the back end (CWE clustering and LLM triage). Measuring each stage tells you where a miss happened — a variant lost below the cutoff is a recall problem (better embeddings, lower threshold), a variant killed by an over-eager verdict is a precision problem (loosen the triage prompt).
De-duplicate the queue by CWE. Before a human or the LLM looks at anything, cluster the surviving candidates by their bug class. A single overflow seed frequently ranks a dozen near-identical copies — the same read-length-then-copy shape pasted across a protocol layer — and reviewing all twelve is wasted effort. Group them under one CWE (CWE-120 for the classic buffer overflow, CWE-787 for the out-of-bounds write it causes, CWE-78 for a command-injection family, CWE-134 for format strings), review one representative per cluster, and let a confirmed verdict on the representative raise the priority of the rest. Clustering also exposes the shape of a finding: twelve variants in one file is a single careless module; twelve variants across twelve files is a systemic convention worth reporting as a class, not twelve tickets.
Measure against a labelled set. Build a small ground-truth corpus: a handful of known variants of some bug (positives) mixed into a body of safe functions (negatives) — you can bootstrap this from a CVE cluster where the vendor’s fix commits tell you exactly which functions were vulnerable. Then score the ranking with the standard retrieval metrics:
- Recall@k — of all the true variants, what fraction appear in the top k? This is the one that matters most for variant analysis: a missed variant is a shipped bug.
- Precision@k — of the top k, what fraction are real? This measures how much triage effort you waste.
- Mean reciprocal rank / MRR — how high does the first true variant land? A proxy for “how fast do I get a win.”
# evaluate.py — recall@k / precision@k against a labelled set
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from index_build import embed
# labelled corpus: list of (function_body, is_variant)
labelled = load_labelled_set() # your ground truth
seed = embed(open("confirmed_bug.c").read())
vecs = np.vstack([embed(b) for b, _ in labelled])
sims = cosine_similarity([seed], vecs)[0]
order = np.argsort(sims)[::-1] # ranked best-first
truth = np.array([lbl for _, lbl in labelled])
for k in (5, 10, 20):
topk = order[:k]
hits = truth[topk].sum()
total = truth.sum()
print(f"k={k:<3} precision={hits/k:.2f} recall={hits/total:.2f}")Setting the threshold. Cosine scores are not probabilities, so pick the cutoff empirically from the labelled set: choose the similarity value that keeps recall high (you want all variants) while trimming the long tail of safe lookalikes. In practice you tune for recall and accept the false positives, because the next stage exists precisely to remove them.
The LLM-triage stage is a precision filter. Ranking is deliberately high-recall and low-precision; the local-LLM verdict then removes the safe lookalikes that shared vocabulary with the seed (the dup_trim problem from the real run). Chaining a high-recall ranker with a precision filter gives you both — but only if you measure each stage, so you know whether a missed variant was lost by the ranker (raise recall / better embeddings) or by an over-eager triage prompt (loosen the filter).
The honest ceiling. No amount of tuning changes the fundamental contract: embeddings rank, they do not confirm. A perfect Recall@20 means every variant is somewhere in your top 20 — it does not mean any of them is exploitable. A behaviourally-identical variant written in a very different structure can still fall below your cut, and a confident LLM verdict can still be wrong. The metrics tell you how good your shortlist is; the confirmed finding is still a fuzz crash or a human proof. Treat evaluation as a way to trust your queue, not to skip the last mile.
A realistic end-to-end case
Put the pieces together and the leverage compounds. Here is how a single finding turns into a systematic hunt, walking the full pipeline.
The seed. During a manual review of an IoT firmware SDK you find one unsafe function: parse_tlv() reads a length field from an attacker-supplied packet and memcpys that many bytes into a 128-byte stack buffer with no check. You confirm it — a stack overflow, attacker-controlled length and content. That is your root cause and your seed.
Rank. You already have a FAISS index of the SDK’s ~40,000 functions, embedded locally with a code-aware model and kept fresh by CI. You paste parse_tlv() in as the seed and query for the top 20 nearest neighbours. It returns in under a second. The list is telling: three functions score above 0.80 — parse_ext_tlv(), read_option(), and decode_attr() — all in the same protocol layer, all following the same read-length-then-copy shape. Below them, scores drop off into obviously-unrelated code.
Line up the seed against its top-ranked neighbour and the shared root cause is obvious — same shape, different clothes, different file:

This is what “semantic, not textual” means in practice. A grep for the seed’s exact memcpy line would never surface parse_ext_tlv — the length is read from a different offset, with a different helper, into a different-width integer — yet the embedding places the two functions as near neighbours because the data flow is identical: packet length → unchecked → memcpy destination bound. The shared, unchanged line (the memcpy with no len <= sizeof(buf) guard) is the bug both functions inherit.
Static-analysis cross-check. You run the unbounded-copy Semgrep rule across the tree. It flags 61 functions — far too many to review — but all three of your high-ranked candidates are in the flagged set, which raises confidence that they are structurally real, not embedding artefacts. The 58 others are deprioritised: Semgrep says “syntactically possible,” but the ranker says “does not resemble the confirmed bug.”
Triage. You feed the three top candidates to the local LLM with the root cause as context: “the confirmed bug copies an attacker-controlled length into a fixed buffer without validation; does this function have the same flaw?” Two come back VULNERABLE with coherent reasoning; read_option() comes back SAFE — the model notices it clamps the length to sizeof(buf) first. You read read_option() yourself to be sure, agree, and drop it. Two live candidates remain.
Fuzz-confirm. These two are now worth real effort. You build a small harness that feeds mutated TLV packets into each, hand it to the fuzzer, and within minutes get an ASAN stack-buffer-overflow crash in parse_ext_tlv() — attacker-controlled length, exactly the seed’s shape. The second candidate does not crash quickly; you keep it in the queue for a longer run and a closer manual look.
The result. One manually-found bug became, in an afternoon, a second confirmed overflow and a third under investigation — plus the knowledge that 58 Semgrep hits are low-priority. No stage did the whole job: the embedding ranking found the family, static analysis vouched for structure, the LLM killed a false positive, and the fuzzer produced the proof. And because every step ran locally, the whole hunt stayed inside the NDA. That is the compounding leverage of the pipeline — the next bug you find becomes the next seed against an index that only gets more valuable.
Limits and honest expectations
Keep the claims grounded. Embeddings do not find novel bug classes — they find more of what you already found. They will miss a variant that is behaviourally similar but lexically and structurally very different, and a weak embedding will mis-rank (as we saw). The LLM triage stage hallucinates too, so treat its verdict as a strong prompt to look, not a conclusion. And none of this replaces the human judgement of deciding what the seed bug even is — that framing is still the researcher’s job. What the pipeline buys you is leverage: one root cause, systematically hunted across a codebase far larger than you could read.
Key takeaways
- Variant analysis — “find one, find many” — is one of the highest-leverage moves in vulnerability research: a single root cause usually has many instances.
- Grep finds syntactic matches; embeddings find semantic ones, ranking code by resemblance to a known-bad pattern even across renames and refactors.
- The winning architecture is two stages: embeddings rank (shrink the haystack), then a local LLM triages the shortlist into an actionable verdict.
- Embedding quality matters — our TF-IDF baseline put the worst bug at #1 but mis-ranked a subtler one; code-aware embeddings fix this as a one-line swap.
- Embeddings rank, they do not decide. Seed from real findings and patch diffs, combine with static analysis and fuzzing, and run it all locally for NDA-covered code.
Conclusion
AI-assisted variant analysis is a concrete, high-value application of AI to security research: it will not invent a new bug class, but it will find the eleven cousins of the one you just reported, across a codebase too large to read by hand — privately, with local models. Combined with static analysis and fuzzing, it turns a single finding into a systematic hunt, which is exactly the workflow we teach in Advanced AI Security.
References
- Google Project Zero — Variant analysis and the “find one, find many” methodology. https://googleprojectzero.blogspot.com/
- GitHub — CodeQL and variant analysis. https://codeql.github.com/
- scikit-learn — TfidfVectorizer and cosine similarity. https://scikit-learn.org/stable/modules/feature_extraction.html
- Microsoft Research — CodeBERT and code embeddings. https://github.com/microsoft/CodeBERT
- Ollama — Local model and embedding endpoints. https://ollama.com/
- Semgrep — Lightweight static analysis for finding bug patterns. https://semgrep.dev/
- Nomic — nomic-embed-text open embedding model. https://ollama.com/library/nomic-embed-text
Reminder: embeddings rank candidates by resemblance; they do not confirm bugs. Treat the ranked list as a prioritized review queue and the LLM triage as a strong prompt to look — the confirmed finding is always a human judgement.
Get in Touch
Want to learn these techniques hands-on, or need help assessing your own mobile or AI stack? We run live and on-demand trainings, offer mobile-security certifications, and take on penetration-testing engagements. Pick the door that fits.
We respond within one business day. Visit our events page to see where we'll be next.


