Dissecting Windows Malware Series - RISC vs CISC Architectures - Part 4
All parts in this series
- 1 Dissecting Windows Malware Series - Beginner To Advanced - Part 1
- 2 Dissecting Windows Malware Series - Process Injections - Part 2
- 3 Dissecting Windows Malware Series - Understanding Cryptography and Data Encoding - Part 3
- 4 Dissecting Windows Malware Series - RISC vs CISC Architectures - Part 4
- 5 Dissecting Windows Malware Series - Creating Malware-Focused Network Signature - Part 5
- 6 Dissecting Windows Malware Series - Explaining Rootkits: Practical Examples & Investigation Methods - Part 6
- 7 Dissecting Windows Malware Series - Unpacking Malware, From Theory To Implementation - Part 7
In the previous article Part 3, we saw an example of how understanding Data Encoding mechanisms can push us forward in:
- Identifying the type of encoding the malware uses
- What are the key functions we need to understand to perform the decoding stage accurately
- How should we these pieces of information as pivot to understand the bigger picture
Now before heading on to Network Traffic Analysis, we’re going to talk about CPU architectures.
Table of Contents
- What’s In It For Me
- RISC vs CISC
- A Bit of History – The Tale of RISC and CISC
- Chapter A – Grandpa CISC
- Chapter B – RISC RISC RISC
- So, What Are the Pain Points and Gains on Each Side
- A Brief Explanation of Addressing Modes
- Important Points That Have Received Less Attention So Far
- The Response of CISC Processors to the Advantages of RISC Processors
- The Emergence of RISC-V Processors
- What Have We Talked About
- But How Is It Related To Malware Analysis
- References
What’s In It For Me❓
We’ll see the differences between RISC and CISC CPU architectures, and examine how that knowledge might be useful to us as Malware Analysts.
RISC vs CISC
CISC processors, or Complex Instruction Set Computers, aim to perform an action (or a set of actions) with the minimal possible number of assembly code lines.
This is achieved by a processor capable of decoding and executing an ISA (Instruction Set Architecture) characterized by a wide variety of assembly commands.
The ISA is essentially a collection of assembly commands that define the processor’s architecture, featuring specific commands like jmp, mov, add, etc., which the processor “recognizes” and can translate into machine language for execution.
The ISA is also characterized by the registers it “recognizes,” though we won’t delve into that aspect here.
RISC processors, or Reduced Instruction Set Computers, aim to perform an action (or a set of actions) in a single clock cycle—often referred to in professional jargon as “One Clock Cycle.”
This goal is achieved by simplifying the ISA to a more limited set of commands that are designed to complete their tasks within a single clock cycle.
 Image : RISC vs CISC
Image : RISC vs CISC
A Bit of History – The Tale of RISC and CISC
Chapter A – Grandpa CISC👴
In the late ’70s, when CISC processors were just beginning to be developed, memory (RAM) was a very expensive commodity.
Existing compilers were still in their infancy and didn’t perform as well as they do today, prompting people to write programs in Assembly code themselves.
Due to the high cost of memory, there was a necessity to find solutions for preserving it and using it in the most efficient way possible.
It was concluded that creating an ISA (Instruction Set Architecture) composed of CPU instructions with broad functionality could address this need.
This meant that a single command, represented by a single Assembly command, despite being complex for the processor to execute - could perform many tasks, allowing programmers to utilize it effectively.
However, this approach soon revealed several problems for a variety of reasons:
- The processor uses a Decoder to decode the Assembly command. Due to the wide functionality of the commands, they varied significantly in terms of encoding/presentation in machine language, etc. Creating a Decoder capable of decoding every such Assembly command, or even several Decoders, was, to put it mildly, a significant headache.
- The temporary solution for the Decoders, which also became the second issue with CISC processors, was to invent something called Microcode.
Similar to how modern programs use subroutines or functions that can be called repeatedly, Microcode was employed in the same way.
For each command in the ISA, a small program was created and allocated a specific place in the CPU memory, composed of even smaller instructions called Microcode.
Thus, the CPU would have a small set of Microcode commands that could be expanded with more complex instructions simply by adding a small Microcode program inside the processor.
Over time, it was realized that the continuous addition of Microcodes began to become a significant headache just as well.
Fixing any bug in the Microcode was a serious challenge since it wasn’t easy to test the code as before.
This led to the realization that perhaps there was another way to approach this problem.
Chapter B – RISC RISC RISC
Aside from the challenges encountered in implementing CISC processor architecture, a shift occurred due to several factors:
- The significant reduction in the cost of RAM.
- Advances in compiler technology.
- A move by programmers towards programming in “higher-level” languages rather than assembly code.
These developments facilitated the transition to using RISC processors.
It was recognized that in terms of performance, the same or even better results could be achieved using simpler commands instead of a few complex commands, where each command is highly complex.
Additionally, it was discovered that the frequency of using these complex commands in CISC processors was not as high as expected, and the cost outweighed the benefits.
This led to the conception of the RISC philosophy: Rather than employing a wide ISA composed of many complex instructions, the shift was towards a narrow ISA consisting of a few simple instructions.
These simple instructions could be used to implement the functionality of the complex instructions as needed.
The focus shifted towards software optimization, leaving the resolution of Microcode-related issues and hardware adjustments to compiler developers.
This approach also underscored the concept of “Reduced” in RISC, emphasizing the reduction in instruction complexity.
The simplicity here pertains to the hardware implementation within the processor, which would use fewer resources and thus simplify the compiler’s task, rather than simplifying the programming process for developers.
Consider the following example that illustrates a code snippet written for MIPS processors (RISC) in Assembly:

-
Values are loaded from memory using load commands (lw = load word).
-
A multiplication operation is then performed between these values using the mult command, with the product’s value stored in the lo and hi registers (representing the lower 32 bits and the higher 32 bits of the product, respectively).
-
The value from the lo register is transferred to the t1 register.
Finally, the product’s value is stored back into memory using the store command (sw = store word).
In contrast, when performing a similar multiplication task in 8086 (CISC) Assembly, the operation is considerably more complex, involving memory access, computation, and storing the result in a target register—all within a single command.
This highlights the complexity inherent in CISC architectures compared to the simpler, more efficient approach favored by RISC architectures.

Side Note
The operations in lines 17-18 (in the MIPS Assembly code) could potentially be optimized further.
However, the primary focus here is on the fundamental differences between the architectures.
This example illustrates the contrast in approach and underlying philosophy between CISC and RISC architectures, which will be explored further in the next paragraph.
The principle we aimed to illustrate is rooted in the differences between the architectures, which is represented in the diagram below:
These differences significantly influence how each architecture operates, reflecting the foundational philosophies or “schools” upon which they are based.
We will explore these distinctions in more detail in the following paragraph.
So, What Are the Pain Points and Gains on Each Side❓
As mentioned earlier, the motivation behind inventing the RISC architecture stemmed from the simple realization that:
People, in reality, rarely write in Assembly anymore. So, why not develop a simpler architecture than CISC, one that the processor can translate and execute more easily?
Therefore, RISC was designed primarily to optimize compilers rather than for direct human use.
Let’s briefly summarize the nuances between the two architectures:
| CISC Architecture | RISC Architecture |
|---|---|
| The ISA includes commands that may span more than a single clock cycle. | All commands in the ISA are designed to be uniform and are guaranteed to complete within a single clock cycle. |
| Hardware-Centric Design - Emphasis is placed on the ISA to maximize hardware utilization optimally. This approach is evident in hardware improvements, such as increasing the number of transistors for a more efficient implementation of instructions. | Software-Centric Design - Responsibility lies with the programmer to ensure code efficiency and compiler performance, rather than focusing on hardware intricacies. |
| Efficient Use of RAM Memory - Fewer commands need to be loaded into memory since each command is complex and offers extensive functionality. | Less Efficient Use of RAM Memory - More commands must be loaded into memory because achieving certain functionalities requires more commands. |
| Supports Microcode: A single command can function as a small program. At the same time, many commands differ from each other in their representation, variable sizes, and command sizes. | A single layer of commands, each of the same fixed size. |
| Memory-To-Memory Operations: Explained in the next paragraph. | Register-To-Register Operations: Explained in the next paragraph. |
| Diverse Addressing Modes - The system incorporates a variety of addressing modes. | Single and Predefined Addressing Modes - The system employs straightforward and specific addressing modes. |
A Brief Explanation of Addressing Modes🔠
Addressing modes describe the various methods used to fetch data.
For instance:
- Using a constant variable to represent the address from which fetching continues.
- Employing relative addresses, such as the PC-Relative addressing mode found in MIPS processors, which operates in this manner.
- Utilizing absolute addresses, for example, in MIPS processors, this approach is used to calculate jump addresses.
- There are several other addressing modes as well.
Important Points That Have Received Less Attention So Far
A central concept that emerged with the advent of RISC processors is pipelining.
We’ll use an industrial laundry to illustrate this principle:
Imagine a large industrial laundry where workers process incoming clothes. They face a huge pile of laundry needing washing, involving several steps:
- Take a smaller pile from the large pile and place it into an available washing machine.
- Once the washing cycle is complete, transfer the clean clothes to the dryer.
- After drying, place the clean clothes on the folding table.
- Fold the clothes at the table.
- Sort the clothes according to customers in the organizing closet.
Note: The pipeline diagram referenced here is available in “Computer Organization and Design” by David A. Patterson and John L. Hennessy (ISBN: 0124077269).
Comparing this process to command execution: traditionally, one command would complete in full before the next began.
For instance, after the washing machine finished its half-hour cycle, only then would we start the next phase, moving the clothes to the dryer, and so forth.
This method, where the total execution time equals the sum of all individual stages, is highly inefficient.
However, if we ensure all stages take the same amount (or at least a similar amount) of time, we can leverage the pipelining principle.
What does this mean?
If every command takes the same time to execute, as soon as one batch of laundry finishes in the washing machine, it can be moved to the dryer, and a new batch can start washing.
This way, we don’t need to wait for one batch to complete all five stages before beginning with the next batch, optimizing the entire cleaning process.
This process is feasible because each stage (or in the context of processors, each command) takes the same time, preventing any “bottlenecks” where commands are delayed due to one taking significantly longer than others.
RISC architecture designers understood this principle well.
This explains the features we previously discussed: one clock cycle per command and uniform command sizes (32-bit) to ensure decoding occurs in roughly the same time frame for each command, among other features.
Load/Store Architecture versus Memory-To-Memory Architecture🕙
RISC architecture, also known as Load-Store architecture, utilizes Load and Store commands to access the main memory (RAM) for reading and writing purposes.
To leverage the pipelining principle effectively, it’s crucial that all commands are executed within the same order of magnitude regarding execution time.
Therefore, in RISC architecture, loading and storing to the main memory are allocated a separate stage in the pipeline.
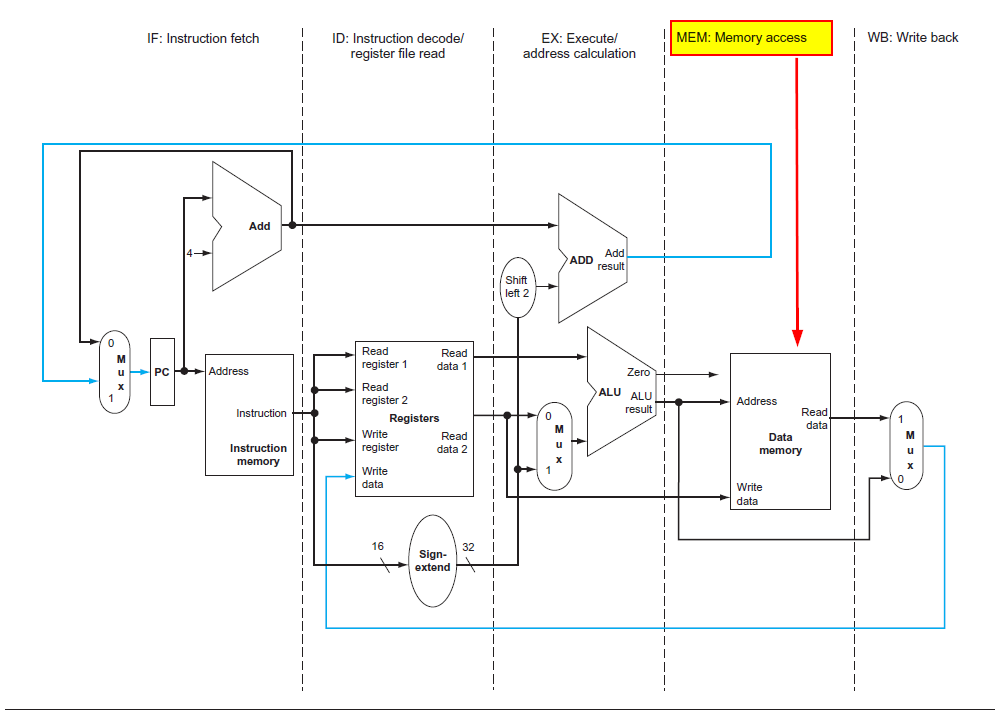
These commands, due to accessing RAM and not working with values already in the registers, require more time. To maintain uniform command execution times, they are given their own stage in the pipeline.
In contrast, CISC processors allow certain commands to load data from main memory, perform operations like addition, subtraction, or multiplication, and directly write back to the memory, hence the term Memory-To-Memory or “memory crossing.”
While this may seem more efficient, such commands significantly extend the execution time within the pipeline compared to other commands.
The RISC approach, favoring splitting such tasks into multiple separate commands, ensures each command is executed in its stage, allowing subsequent commands to proceed without delay.
Moreover, the inclusion of compound commands—entailing memory reading, ALU operations, and memory writing—is contrary to RISC processors’ simplicity principle.
In RISC, all operations are performed on data within the registers—hence the name Register-To-Register. Loading from and storing back to main memory occur in distinct stages, as do ALU operations, with values first saved back in the register before being written to memory in a separate stage.
Multiple Registers🔖
Earlier, we discussed how RISC processors are perceived as less efficient in utilizing RAM, requiring more “simple commands” to perform actions that CISC processors might accomplish with far fewer commands.
Consequently, this necessitates loading more commands into the RAM.
The solution offered by RISC architecture to this challenge is the increased use of registers.
The innovators behind RISC architecture realized that most commands involve reading and writing data from memory to perform operations on this data.
So, why not allocate more registers for the CPU’s use?
By doing so, more information can be transferred from memory to registers, minimizing the need for memory access.
A point to contemplate on: If that’s the case, why not add a significantly large number of registers, especially considering RISC processors typically make do with only 31…
This approach necessitated thorough analysis to determine when information needs to be stored in a register, when it should be written back to memory, and other intricate details—largely demanding substantial advancements in compiler technology.
Herein lies a benefit of RISC processors: their addressing modes are considerably more restricted, simplifying these modifications.
This article will not delve into that topic.
The Response of CISC Processors to the Advantages of RISC Processors❗
The developers behind CISC processors did not simply stand by idly in the face of RISC processors’ advancements.
They began to incorporate principles and characteristics of RISC processors into their designs.
Realizing the necessity to remain competitive, they sought ways to implement pipelining within their processors, a challenge given the architecture at the time.
Their solution was to make the inner workings of CISC processors as similar to RISC processors as possible.
This involved decoding commands in the CISC architecture and then breaking them down into simpler commands known as micro-operations.
Similar to commands in RISC processors, these micro-operations could then be processed in the pipeline due to their more predictable execution times and comparable durations.
While the topic of micro-operations is fascinating, we won’t delve into it further here, but feel free to explore more at the following link:
https://erik-engheim.medium.com/what-the-heck-is-a-micro-operation-e991f76209e.”
The Emergence of RISC-V Processors📈
In a notable shift, we turn our attention to RISC-V processors.
You may or may not have encountered this buzzword, but it has been gaining traction in technology circles recently—and for good reason.
RISC-V processors are often heralded as the “Linux of CPUs.”
However, their open-source nature is not the only remarkable aspect.
Much like the open-source principle revolutionized software, we’re beginning to see its influence extend into other realms, including hardware.
Among the benefits of RISC-V processors:
- Their Instruction Set Architecture (ISA) is non-incremental. What does this mean?
Traditional ISAs like x86, MIPS, and ARM accumulate additional commands over time, leading to bloated and complex ISAs.
For instance, the x86 ISA includes over 1500 different commands, many of which are rarely, if ever, used.
RISC-V opts for a modular approach based on extensions.
Unnecessary commands can be excluded, resulting in a streamlined set of instructions. This modularity affords several advantages:
-
RISC-V processors are simpler to implement, requiring a minimal ISA and fewer transistors.
-
This simplicity can contribute to higher clock frequencies, enhancing processor performance. While it’s somewhat simplistic to attribute performance solely to clock speed—since other factors play a role—it’s undeniably a significant factor.
-
A Unique Aspect of RISC-V Processors
Interestingly, the RISC-V Foundation doesn’t manufacture RISC-V processors.
Instead, it produces a specification — a kind of ‘agreement’ among software developers, hardware developers, and others who adopt this specification.
This agreement ensures that RISC-V processors conform to the provided specifications.
What compels adherence to this “contract,” especially without legal enforcement or the threat of lawsuits?
The answer to that might be more nuanced than expected, inviting deeper contemplation.
So Today, Aren’t RISC and CISC the Same?
With everything we’ve discussed, the distinction between CISC and RISC architectures seems to be blurring, doesn’t it?
CISC developers are beginning to incorporate micro-operations to facilitate pipeline processing, while some RISC developers are adopting technologies such as compressed instruction sets and hyper-threading, traditionally associated with CISC processors (these topics, due to their complexity deserve a separate article).
It appears that the differences, at least those perceptible to the casual observer, are gradually diminishing.
However, the fundamental essence that characterizes each architecture remains unchanged:
- RISC processors are defined by their use of fixed-size commands, in contrast to the variable-sized commands of CISC processors.
- RISC based systems emphasize the standardization of commands and efficient pipeline utilization, whereas CISC based systems may employ supplementary techniques to address gaps in their custom pipelines.
- The distinction is clear in the load/store approach of RISC processors, where memory access is executed through specific, dedicated commands, as opposed to the memory-to-memory approach of CISC processors, which allows actions like memory access, address or value computation, and memory write-back within a single command.
- RISC favors the use of multiple registers to reduce memory access frequency, whereas CISC typically utilizes a more limited number of registers.
In summary: While RISC architectures offload much of the computational heavy lifting to the compiler, enhancing performance, CISC architectures enable more complex operations, such as various memory access modes, offering solutions in many scenarios.
So Where Are We Actually Going?
It turns out that not all ISAs “are created equal in the image of God” and the ISA of a particular processor can significantly affect the way the CPU itself is designed – in terms of hardware.
The specific ISA chosen can simplify the design process of creating a high performance processor that consumes as few resources as possible.
That’s why in recent years Apple wants to create tailor made solutions for their computers/smartphones with specialized hardware capable of providing solutions in areas such as:
- Machine Learning
- Encryption
- Face Recognition
- and much more
While the guys at Intel with competing x86 processors are forced to do all this with an external chip – because of the CISC architecture they are based on.
Apple aims to do everything in a large integrated circuit or in other words – System on a Chip (SoC).
This shift in approach has long arrived to smartphones since due to their size, they do not have the privilege of another external chip (all components including: CPU, GPU, Memory, Specialized Hardware, and others) everything must be implemented in a single circuit and that’s why ARM is very dominant in the smartphone market (based mainly on RISC processors).
We are already seeing recently that laptops are starting to rely on Tight Integration, all implemented in a single Integrated Circuit – it provides a noticeable improvement in performance, and the next step is that even PC computers will be implemented this way.
What Have We Talked About
We explored the distinctions and implementations, at a high-level overview, of RISC versus CISC architecture.
We delved into the history of CISC processors and the rationale behind the development of RISC processors.
With that being said, you sure have noticed that CISC processors still hold a significant market share, despite the advantages of RISC.
This situation involves intriguing dynamics related to x86 processors – if you’re looking for some intriguing insights, I recommend doing a bit of research.
We highlighted many benefits of RISC processors in comparison to CISC processors and touched upon several key concepts in architecture, including:
- Pipelining
- Load/Store architecture versus Memory-To-Memory
- Multiple registers versus a limited number of registers
We briefly discussed the emerging RISC-V architecture, which offers tailor-made chips, allowing you to select which instruction set extensions are included in your ISA – quite a revolutionary concept!
We also considered the current direction of technology in this dynamically evolving field, hinting that future shifts might lead us toward entirely different technologies and methodologies.
It’s crucial to acknowledge the topics we didn’t cover in depth, as they represent complex areas that are challenging to explore independently:
- Although mentioned briefly, microcode versus micro-operations constitute an expansive subject that enthusiasts will find fascinating.
- The latest optimization strategies, particularly those considering security aspects: Hyper-Threading versus Hardware-Threading.
- We used an industrial laundry as an analogy for the pipeline, yet there are many more technical nuances fundamental to the operation of RISC processors and CPUs in general.
The pipeline is divided into five stages: Fetch, Decode, Execute, Memory, Write-Back.
There are also data hazards and control hazards stemming from the parallelism it facilitates – indeed, a whole other realm of discussion.
The concepts of latency and throughput – while not overly complex, these are important to understand.
The question of where cache memory fits into all of this wasn’t addressed, even though it plays a crucial role in various technologies and, by extension, processor architectures.
For those wishing to explore further, head to the References section for some resources.
But How Is It Related To Malware Analysis?
Following the extensive architectural knowledge we learned in this crash course, you probably already see how it can benefit a Malware Analyst:
Optimization Techniques:
Malware often uses various optimization techniques to run efficiently on target systems. RISC architectures, with their simpler and fewer instructions, tend to execute programs faster than CISC architectures in certain contexts.
Knowing the targeted architecture can help analysts understand the malware’s optimization strategies.
- Assembly Language Analysis:
Malware analysis involves examining the assembly code generated by the malware. Since CISC and RISC architectures have different instruction sets, the assembly code will look different.
Understanding these differences can help analysts more accurately disassemble and analyze the binary code of malware to understand its functionality and purpose.
- Payload Design:
Some malware payloads are designed specifically for the nuances of a particular architecture.
For example, a payload exploiting a specific vulnerability in a CISC-based system might not work on a RISC-based system. Knowing the architecture can help analysts determine the intended target of the malware and its potential impact.
- Obfuscation Techniques:
Malware authors often use obfuscation to hide the true intent of their code.
The complexity of CISC instruction sets can be exploited to create more complex obfuscations compared to RISC.
Understanding the architectural differences can aid in deobfuscating and understanding the malware’s true behavior.
And those are just the top of the iceberg🪲
References
Well, the article has reached its conclusion.
The following resources have been a great aid in completing this work:
- An insightful blog by Erik Engheim, excellently written and covering a broad range of topics related to processor architecture: “What Does RISC and CISC Mean in 2020?”
https://medium.com/swlh/what-does-risc-and-cisc-mean-in-2020-7b4d42c9a9de
- A concise and accurate webpage on the differences between RISC and CISC by Stanford University: “Stanford University - RISC vs CISC”
https://cs.stanford.edu/people/eroberts/courses/soco/projects/risc/risccisc/
- Additional informative articles that served as great inspiration:
https://www.microcontrollertips.com/risc-vs-cisc-architectures-one-better/ https://www.baeldung.com/cs/risc-vs-cisc
- The book Computer Organization and Design by David A. Patterson and John L. Hennessy, which was invaluable for its theoretical insights and explanatory images (including those related to laundry and pipelining :)
Get in Touch
Want to learn these techniques hands-on, or need help assessing your own mobile or AI stack? We run live and on-demand trainings, offer mobile-security certifications, and take on penetration-testing engagements. Pick the door that fits.
We respond within one business day. Visit our events page to see where we'll be next.


