Advanced Frida Usage Part 7 - Frida Memory Operations
All parts in this series
- 1 Advanced Frida Usage Part 1 - iOS Encryption Libraries | 8kSec Blogs
- 2 Advanced Frida Usage Part 2 - Analyzing Signal and Telegram messages on iOS
- 3 Advanced Frida Usage Part 3 - Inspecting XPC Calls
- 4 Advanced Frida Usage Part 4 - Sniffing location data from locationd in iOS
- 5 Advanced Frida Usage Part 5 – Advanced root detection & bypass techniques
- 6 Advanced Frida Usage Part 6 - Utilizing writers
- 7 Advanced Frida Usage Part 7 - Frida Memory Operations
- 8 Advanced Frida Usage Part 8 - Frida Memory Operations Continued
- 9 Advanced Frida Usage Part 9 - Memory Scanning in Android
- 10 Advanced Frida Usage Part 10 - Instruction Tracing using Frida Stalker
Introduction
Welcome to part 7 of our Advanced Frida Usage series. In Part 6 of our Frida blog posts, we went over Utilising writers for different CPU architectures. X86Writer for X86 and Arm64Writer for AArch64 CPU architecture.
In this blog post, we will discuss how to use Frida for memory manipulation operations using Javascript API and analysis of Native Android libraries. Some of the Javascript Frida API functions used for memory operations are Memory.scan, Memory.scanSync, Memory.alloc, Memory.copy, Memory.dup, Memory.protect and Memory.patchCode.
In this tutorial, we will focus on some of the API’s used for scanning, reading and writing, copying, and patching process memory.
You can find the APK files at: https://github.com/8kSec/Blog-resources/tree/main/Frida-Series
Analysis
In this blog, we will use a simple Android application that compares two static strings. If the two strings match, Memory is Hooked is displayed, else Hello, World! is displayed.
#include <jni.h>
#include <string>
extern "C"
JNIEXPORT jstring JNICALL
Java_com_ksec_eightksec_MainActivity_stringFromJNI(JNIEnv *env, jobject /* this */) {
// store two comparison strings in memory
const char *stringOne = "Memory Hooked";
const char *stringTwo = "Hello, World!";;
if (strcmp(stringOne, stringTwo) == 0) {
return env->NewStringUTF(stringOne);
} else {
return env->NewStringUTF(stringTwo);
}
}Memory Scanning
The Memory.scan() API in Frida allows the scanning of the target process memory for specific patterns of interest such as strings, binary data, and other structured data.
The API allows scanning a region of memory starting from the specified address of the target process to a specified range(size).
In our example, we will scan for ELF Magic Header specific byte sequence found at the beginning of ELF files. The Magic Header byte sequence is 0x7f454c46 in hex format.
Writing Frida script
We will create a Frida script that will use Memory.scan() function to scan our entire target process memory for the selected pattern.
Steps we need to take:
- Get the target process hooked by Frida
- Write the pattern to search for
- Print the memory representation of the First 64 bytes
- Scan Magic header pattern using
Memory.scan - Print the display address for the matched pattern address.
The implementation script looks like this:
// Script to pattern scan using Memory.scan()
if (Java.available) {
Java.perform(function () {
let eightksec = Process.enumerateModules()[0];
// Pattern (ELF Magic Header)
let pattern = "7f 45 4c 46";
// Print the first 64 bytes of the process
console.log(
hexdump(eightksec.base, {
offset: 0,
length: 64,
header: true,
ansi: true,
})
);
// Memory.scan(address, size, pattern, callback)
Memory.scan(eightksec.base, eightksec.size, pattern, {
onMatch: function (address) {
// Successful Match Message
console.log("Match at: " + address);
},
onComplete: function () {
// Scan complete Message
console.log("Scan complete");
},
onError: function (error) {
console.log("Scan error:" + error);
},
});
});
}Running the Frida script
We will run the script against our application as shown in the image below.
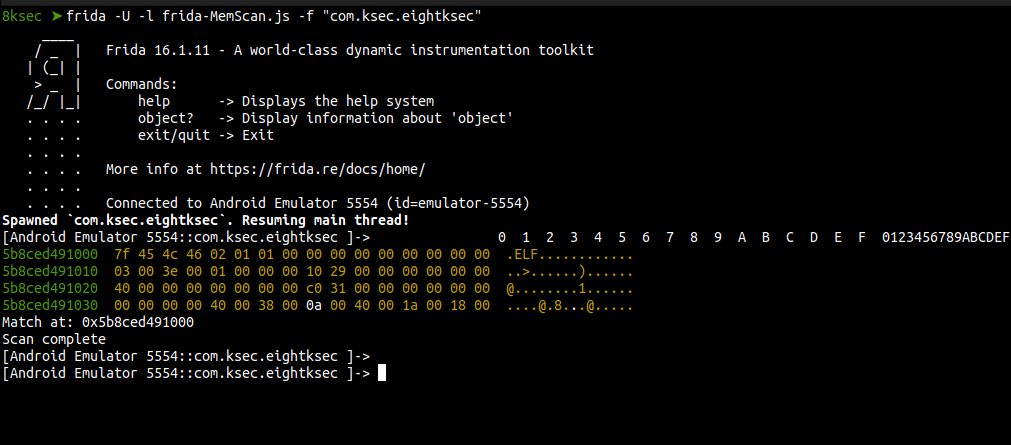
We can see that the results match is the same as the base address of our target process. It means we have successfully found matched pattern instance on the memory.
Memory Reading and Writing
Frida API enables the reading and writing operations which are crucial for inspecting and modifying the runtime of a target process, which is often necessary for debugging, patching, or reverse engineering purposes.
For reading and writing content, we need to be careful with the size we are reading or writing to avoid out-of-bound write/read vulnerabilities. These vulnerabilities may cause the crashing of processes during debugging and exploitation causing instability.
Frida uses Memory.alloc() for the allocation of memory with size passed as an argument to the function.
In our script below we show how to do read and write memory operations on a target process.
Writing Frida script
We write a Frida script to show how various API functions are used for the allocation, reading, and writing of memory.
Steps we need to take:
- Create a simple byte array with string eightksec
- Allocate memory using
Memory.alloc - Write to allocated memory using
Memory.writeByteArray - Read the content from memory using
Memory.readByteArray - Create a function for printing both read and write operations
- Print data representation in memory using the memHexdump function
The full code for our script is as follows:
if (Java.available) {
Java.perform(function () {
//write eightksec as a byte array to our allocated memory buffer
let arrayValue = [
0x45, 0x49, 0x47, 0x48, 0x54, 0x4b, 0x53, 0x45, 0x43, 0x00, 0x00,
0x00, 0x00, 0x00,
];
// Allocate Memory on the heap with the size of the arrayValue
let memAllocate = Memory.alloc(arrayValue.length);
// Memory Write Operation
Memory.writeByteArray(memAllocate, arrayValue);
// Memory Read Operation
let buffer = Memory.readByteArray(memAllocate, arrayValue.length);
// display the memory operation of read/write operations
function memHexdump(value, operationType) {
console.log(operationType);
console.log(
hexdump(value, {
offset: 0,
length: arrayValue.length,
header: true,
ansi: true,
})
);
}
memHexdump(memAllocate, "nMemory WriteByteArray Operation");
memHexdump(buffer, "nMemory ReadByteArray Operation");
});Running the Frida script
Let’s now test our script.
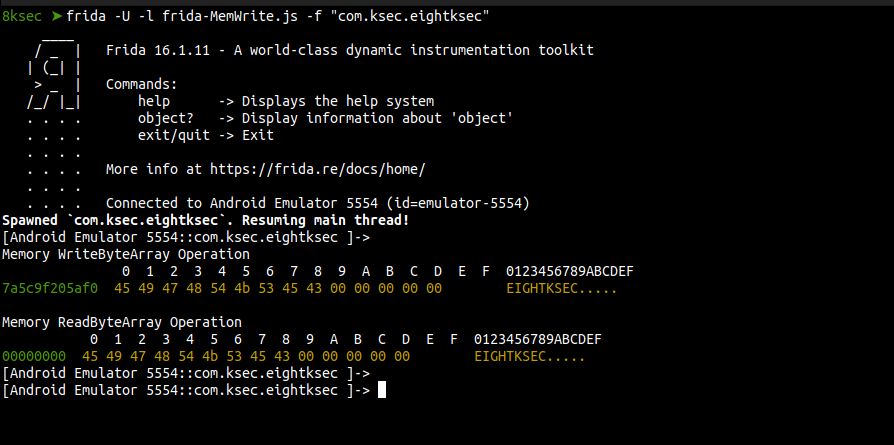
From our output message, we can have succesfully done both read and write operations of our string EIGHTKSEC.
Memory Monitoring
The memoryAccessMonitor API allows observing memory access events in the target process. These access events monitored by the API are read, write, and execute. This allows an understanding of how memory is accessed and modified, which is valuable for debugging, security analysis, and reverse engineering.
This is very helpful in Monitoring read and write operations at the granularity of memory pages. For large applications, it is possible to filter events based on memory regions or access types.
Writing Frida script
Steps we need to take to monitor access events:
- Find target module
- Find the base address of our module (hooked module)
- Convert the base address to a pointer using
ptr - Run
MemoryAccessMonitor.enableon the identified target address - Print the details operation of target address access events, which are read, write, or execute
Here is the full code script implementation for monitoring access events in the hooked process.
// Memory Monitoring Script
if (Java.available) {
Java.perform(async function () {
let eightksec = Process.enumerateModules()[0];
let baseAddress = eightksec.base;
console.log("Base Address:", baseAddress);
let hook_ptr = ptr(baseAddress);
MemoryAccessMonitor.enable(
{
base: hook_ptr,
size: 8,
},
{
onAccess: function (details) {
console.log(
"API Access Details (read | write | execute):",
details.operation
);
},
}
);
});
}Running the Frida script
We run our script and test it out.
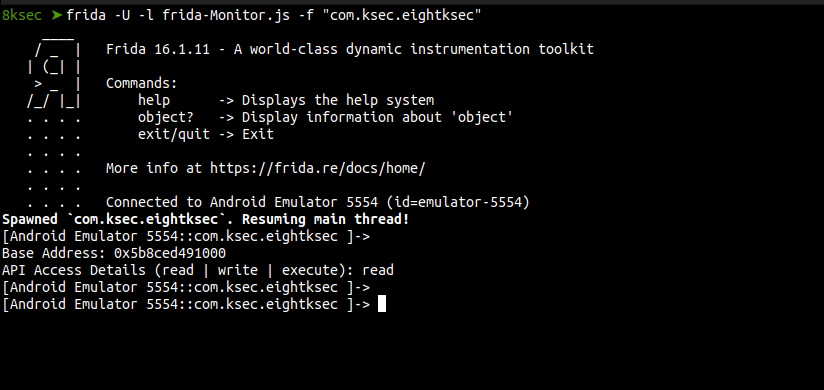
The output of the script shows the read access event was used at the given memory address.
Memory Copying
Memory.copy is used for copying data from one memory region to another. This API capability can be used for various purposes such as patching, modifying data structures, or extracting data from one part of the memory to another.
In our example, we will use Memory.copy API to copy data stored in one Memory address to another address. This can be used as a patch method by making two pointer addresses equal.
Writing Frida script
We will write a script to show the use of Memory.copy in transferring data from one pointer address to another.
The steps we need to take to copy our data from the source address are:
- Get the module to hook
- Get the base address of the module
- Get the pointer address of the source address
- Get the pointer address of the destination address
- Use
Memory.copyto copy the content of the source to the destination and vice versa - Display the output of the copy operation
The script code is:
// Memory operation
if (Java.available) {
Java.perform(function () {
let moduleName = Process.enumerateModules()[0];
let baseAddress = moduleName.base;
console.log("\nMemory before Copy\n");
console.log("Base Address: ", baseAddress);
console.log(hexdump(baseAddress, {
offset: 0,
length: 64,
header: true,
ansi: true,
}));
console.log("\nMemory after Copy\n");
// Allocate some memory
let memAllocated = Memory.alloc(16);
Memory.copy(ptr(memAllocated), ptr(baseAddress), 16);
console.log(hexdump(memAllocated, {
offset: 0,
length: 16,
header: true,
ansi: true,
}));
});
}Running the Frida script
Running the script against our application we can copy the ELF magic header of the application to newly allocated memory.
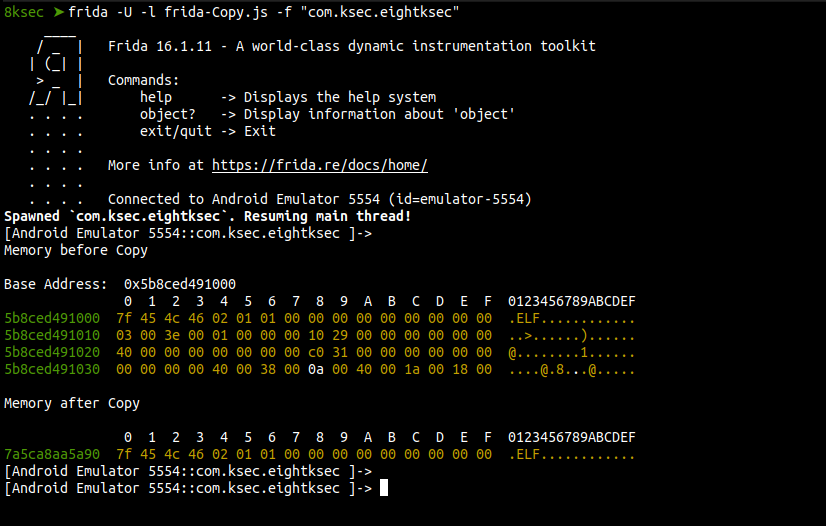
The two hex representation show a successful copy of the ELF header of the application. This can also be implemented in string comparison.
In real-world application pentesting and security research, Frida memory APIs can be used to analyze and manipulate applications memory to uncover security vulnerabilities, understand the internals of the application, patching and secrets exposure for patterns associated with sensitive information.
Conclusion
This marks the end our blogpost on Frida memory operations as part of our advanced Frida series. We have learned how to utilize various Frida APIs for memory inspection and analysis. These APIs can be utilized against real-world applications in inspecting runtime memory for debugging, patching and finding security vulnerabilities.
References
Get in Touch
Want to learn these techniques hands-on, or need help assessing your own mobile or AI stack? We run live and on-demand trainings, offer mobile-security certifications, and take on penetration-testing engagements. Pick the door that fits.
We respond within one business day. Visit our events page to see where we'll be next.


